See How Your Infrastructure Actually Affects Your Applications
Infrastructure tools show you node metrics, but can't tell you why your applications are slow. Devtron reveals the connections, so you fix problems in minutes, not hours.
Powering Mission-Critical Kubernetes for Global Enterprises
The Cost of Siloed Signals
When infra and app signals live in separate silos, every incident turns into guesswork. Operators chase pod logs. Developers check traces. SREs juggle dashboards. Meanwhile, customers keep refreshing a broken page. Every hour lost is wasted revenue, blown SLAs, and burned-out teams. The longer you stay in tool chaos, the harder it gets to move fast or even stay stable.
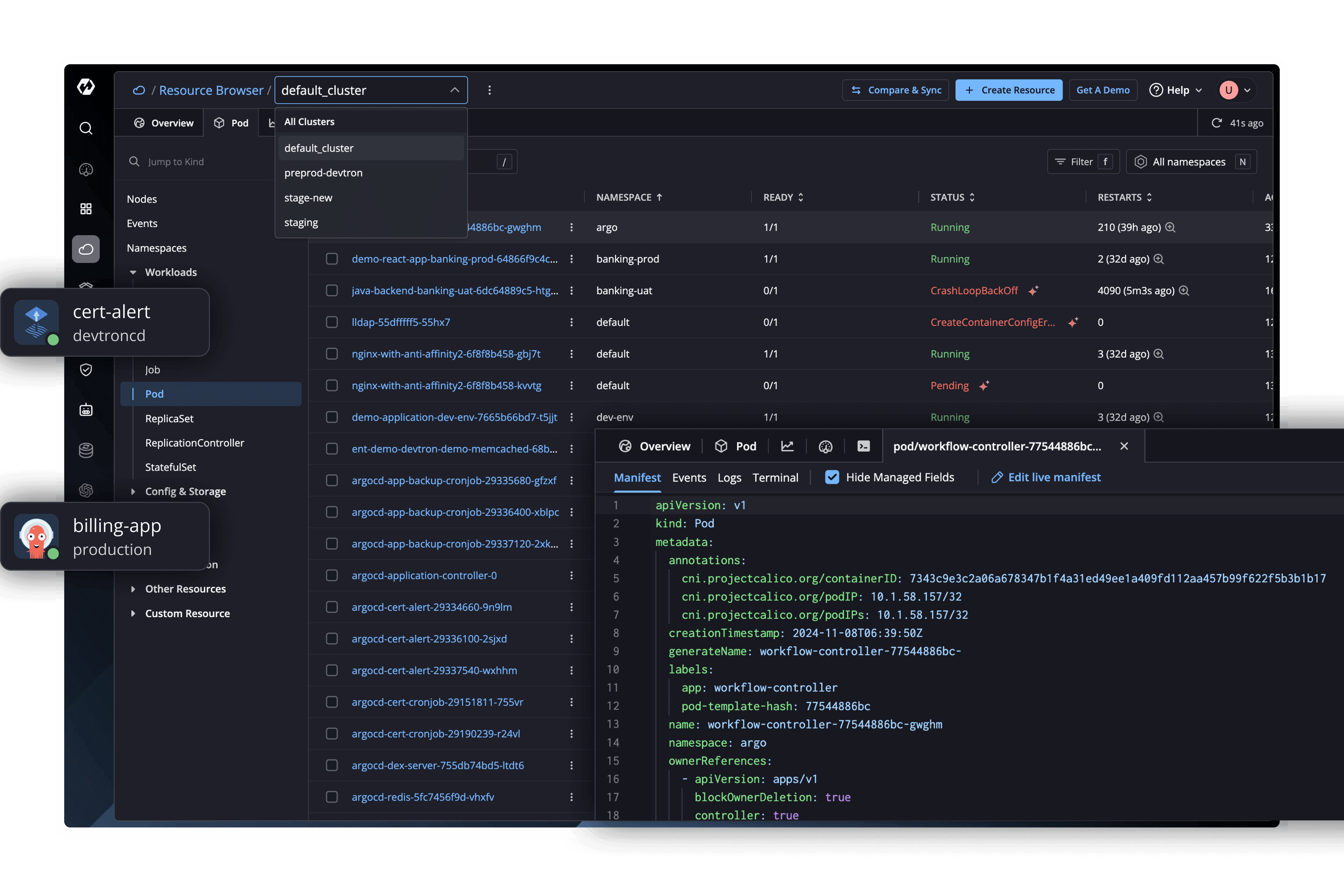
Multi-Cluster & Cloud Operations
One view, all clusters, everywhere
Stop juggling dashboards. Devtron centralizes operations across Kubernetes, on-prem, cloud, or edge.
Cluster & Node Visibility
Unified dashboards show clusters, nodes, workloads, and events.
Context-Aware Navigation
Switch clusters seamlessly without losing context.
One-Click Operations
Pod and node actions from the UI with built-in guardrails.
Comprehensive Monitoring
Metrics, logs, and events all in one view.
Instant Troubleshooting
Access logs, manifests, events, and terminals in a click.

GitOps Fleet Management
All your ArgoCD and FluxCD, one control plane. Multiple GitOps instances don’t have to mean chaos.
Single Control Pane
Manage every GitOps instance from one UI.
Fleet-Wide Visibility
Detect drifts and errors across clusters in real time.
Governance at Scale
Apply consistent policies across teams and environments.
BYO GitOps
Connect existing Argo and Flux without disruption.

Helm Lifecycle Management
Finally, Helm without the headaches.
No more error-prone upgrades or mystery rollbacks.
Visual Release Pipeline
Track every Helm chart through its lifecycle.
One-Click Version History
Compare, roll back, and see exactly what changed.
Centralized Marketplace
Deploy from 100+ pre-verified Helm apps instantly.


Monitoring & Incident Response
Self-healing Kubernetes that actually works.
Instead of chasing errors, Devtron fixes them.
End-to-End Self-Healing
Automated runbooks remediate issues as they happen.
Proactive Monitoring
Detect and resolve errors before users are impacted.
Instant Failure Resolution
Automated fixes trigger immediately.
Upgrade Readiness
Pre-checklists keep upgrades safe and predictable.

Infrastructure Provisioning
One-click clusters across clouds/ Kubernetes shouldn’t require endless scripts or manual tinkering.
One-Click Clusters
Spin up Kubernetes on AWS, Azure, or GCP in minutes.
Standardized Configurations
Enforce compliance and security everywhere.

The
Free Plan That Actually
Covers What You Need
Access essential features without limits or hidden catches—start building with confidence at no cost.
Benefits of Using Devtron

Native integrations with your existing cloud, cluster, and infrastructure

No rip and replace required. Devtron enhances what you have.
The
Devtron
Difference
Discover how Devtron empowers teams to achieve DevOps excellence.
Read what our users have to say about their experience with our platform.








Frequently Asked Questions
What is the Command Center for Kubernetes Infrastructure?
The Command Center is a unified platform that helps teams to centralize, operate, and scale Kubernetes clusters and workloads across multi-cloud and edge environments.
Can this platform handle AI/ML workloads alongside microservices?
Yes. It is designed to support both traditional microservices and GPU-intensive AI/ML workloads, ensuring seamless scaling, monitoring, and governance across diverse applications.
What level of security does the platform provide?
The Intelligent Command Center delivers enterprise-grade security with centralized policy management, role-based access control (RBAC), and real-time monitoring to protect sensitive workloads across all environments.
How does intelligent automation improve Kubernetes operations?
Through automation, the platform reduces manual intervention by handling repetitive tasks like failover, monitoring, and compliance enforcement. This helps teams save time, minimize errors, and ensure faster, more reliable deployments.
