
If you have ever written a code, you might have come across environment variables, which you can simply think of as inputs that your applications take in as parameters. Environment variables come in handy when you deal with lots of different environments such as local, dev, stage, prod, etc.
One of the interesting use cases of using environment variables can be to enable Feature Flags within the product you are building. You can control the product capabilities using environment variables. Additionally, it enables you to define real-time inputs for different environments instead of hard-coded environment variables for different environments.
Environment variable management for front-end applications does not have to be cumbersome. Learn how to simplify your workflow and deploy with ease in all environments. Streamlining this process boosts productivity and gives smoother deployments.
Traditional Approach
Though the environment variables provide a dynamic approach to building your applications, managing them for different environments can be cumbersome especially if you are dealing with cloud-native environments. Building container images for each environment (dev, QA, stage, prod) with the specific environment variables files can reduce the dev productivity and eventually can increase the time for go-to-market.
The traditional approach is to have a separate .env for each environment where all the environment variables required by the application are given. When you are building a container image, the relevant .env file is passed which contains the environment variables for the specific env. If there is any missing/ incorrect values are given, the container image build will be failed.
With this approach, the environment variables are hard-coded for different environments in different .env files, which are used for target environments. Eventually, for the same application, there would be multiple builds corresponding to the environment with different .env files. Some of the disadvantages of such an approach are:
- Increased Complexity
- Prone to human errors
- Decreased developer productivity
- Time-consuming, hence delayed go-to-market
- Low-end security
Kubernetes-native Approach
To store the environment variables and critical data, we have configmaps and secrets in Kubernetes. During the build, a few parameters need to be passed which is required by the application to start the build process. Instead of maintaining multiple .env files for different environments, users can provide placeholder data in .env file which will start the build process and build a container image. Once the container image has been built, the same image can be deployed across different environments.
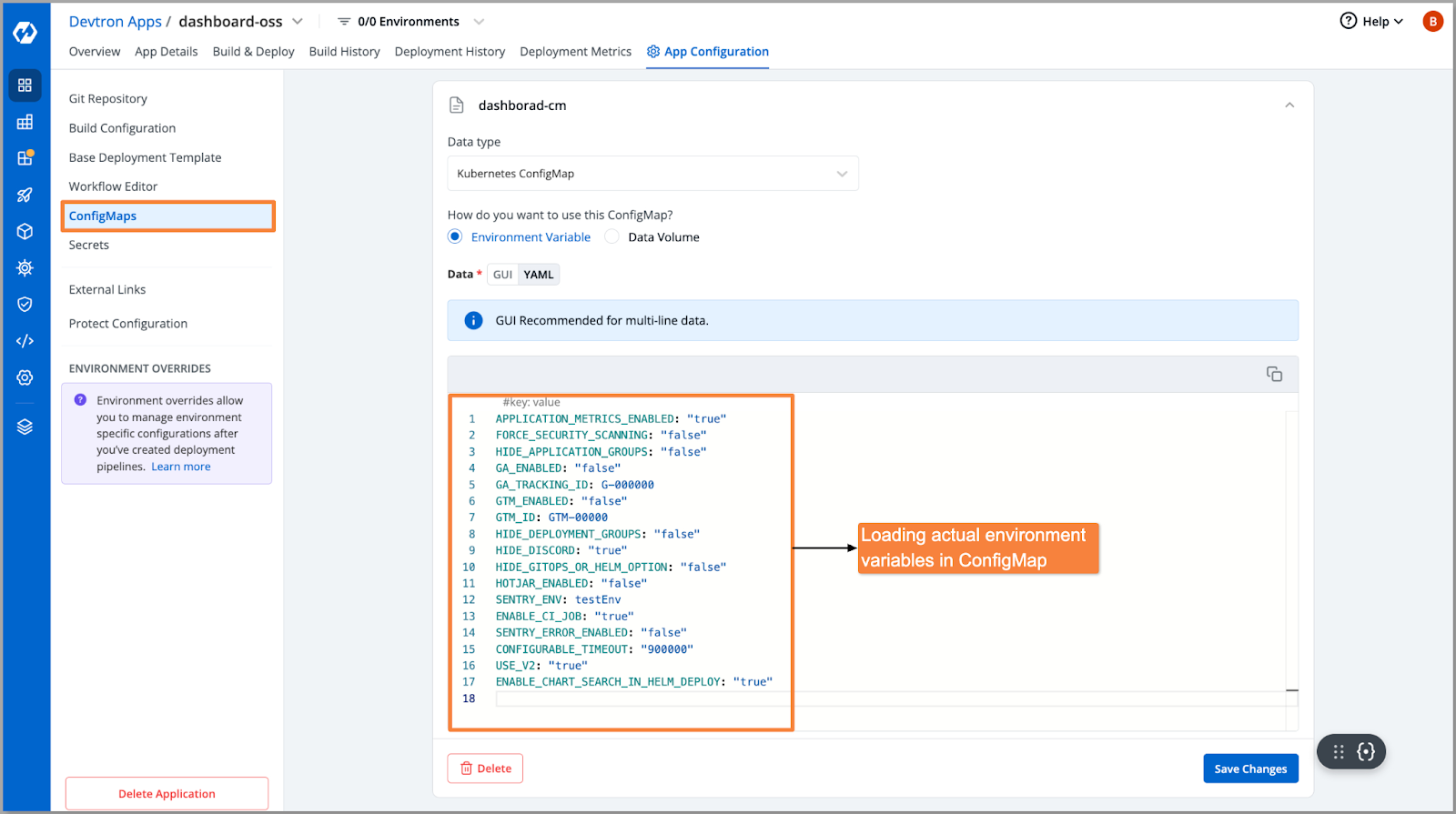
For the target environments where environment variables are different, the user can create configmaps and provide the actual keys and values which can be overridden after the successful deployment.
Let's take an example of how Devtron handles the frontend environment variables of its dashboard which are dynamic in nature and are unique for different customers.
Step 1: Create a file that contains some dummy environment variables and name the file as .env. This file will ensure that the build process will be completed successfully without the requirement of specific environment variables.
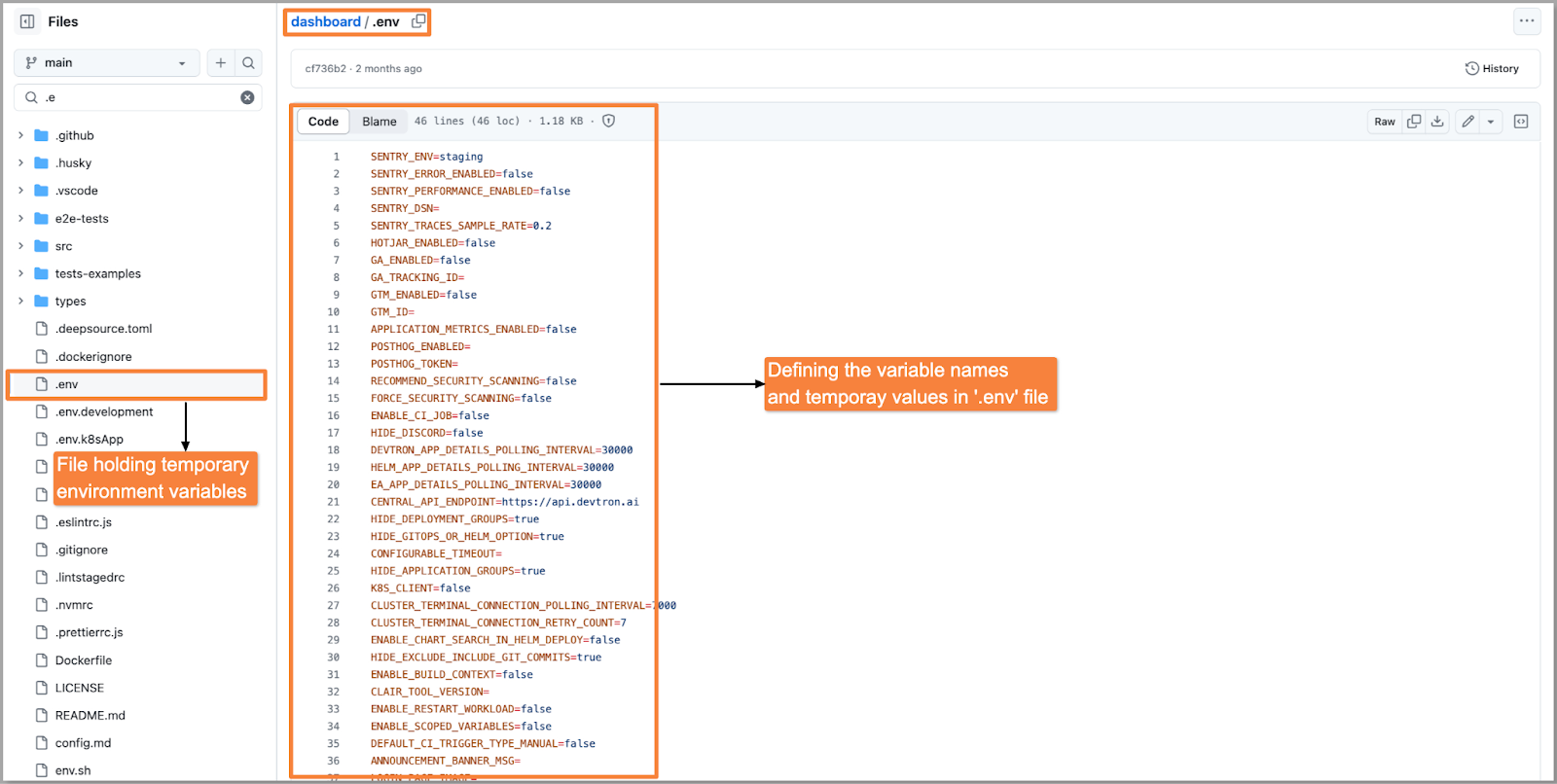
Step 2: Once the build is completed, it needs to be deployed across different environments (dev, QA, stage, prod) where the values would be different for each environment. For respective workflows, you can create a ConfigMap and provide the actual key-value pairs as you can see in the below image.
Step 3: The Dockerfile is configured to run the env.sh script during container initialization. The script will create a new config-env.js file with a window._env_ object which will hold all environment variables. This script will read our default .env file to take the keys and populate their values from the ConfigMap of that environment. If any variable is missing in ConfigMap that will be taken from .env file as default.
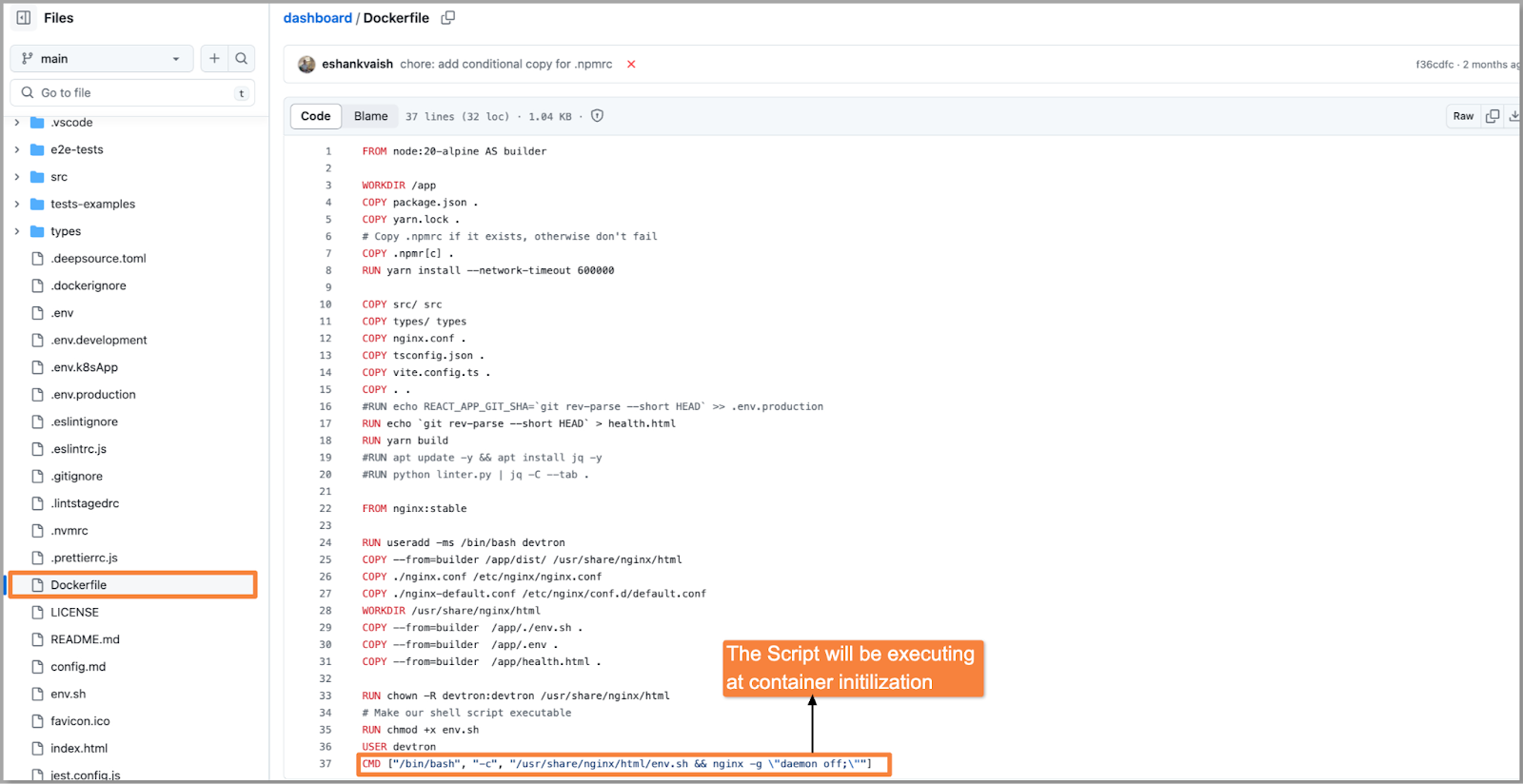
You can execute the following script i.e., env.sh which will replace the dummy environment variables with the values given in ConfigMap for the target environment.
# Recreate config file
rm -rf ./env-config.js
touch ./env-config.js
# Add assignment
echo "window._env_ = {" >> ./env-config.js
# Read each line in .env file
# Each line represents key=value pairs
while read -r line || [[ -n "$line" ]];
do
# Split env variables by character `=`
if printf '%s\n' "$line" | grep -q -e '='; then
varname=$(printf '%s\n' "$line" | sed -e 's/=.*//')
varvalue=$(printf '%s\n' "$line" | sed -e 's/^[^=]*=//')
fi
# Read value of current variable if exists as Environment variable
value=$(printf '%s\n' "${!varname}")
# Otherwise use value from .env file
[[ -z $value ]] && value=${varvalue}
# Append configuration property to JS file
if [[ "$value" == "true" ]] || [[ "$value" == "false" ]]; then
echo " $varname: $value," >> ./env-config.js
else
echo " $varname: \"$value\"," >> ./env-config.js
fi
done < .env
echo "}" >> ./env-config.js
Conclusion
With the implementation of this approach, you can streamline the deployment process for your front-end application across multiple environments. Instead of taking separate builds for each target environment, now you can build your application with default environment variables and later populate the appropriate environment variables. Using the Kubernetes ConfigMaps and a script that will replace the variables automatically.
Feel free to join our Community Discord Server and post your questions if you have any. If you like the platform, feel free to give it a star ⭐️

