
KEDA, short for Kubernetes Event-driven Autoscaling, allows us to scale applications based on events. It can be added to any Kubernetes cluster and works seamlessly with Horizontal Pod Autoscaling. Today, in this blog, we will explore HTTP request-based autoscaling with KEDA.
Why opt for autoscaling applications based on HTTP requests?
a) Consider a scenario where we have multiple applications running on Kubernetes that require substantial computing resources but are only needed for a few hours a day, such as during working hours in a development/QA environment. We could create a custom script to scale down the application using a cronjob to address this. However, this solution falls short when someone needs to work late at night or off-days. There are various cases that a cronjob can miss.
In such cases, scaling the application based on traffic becomes more desirable. If there is an incoming traffic to the application, it should automatically scale up, or else scale it down to zero.
b) There are several metrics available to be used to scale up/down the application like CPU usage, Memory usage, and several scaled object support offered by KEDA, but what if we would like to scale up the application based on the volume of traffic coming (HTTP request)?
Autoscaling with HTTP
The KEDA HTTP Add-on is designed to provide autoscaling capabilities for HTTP servers.
We can scale the application down to zero replicas and scale it up to the desired number of replicas. This helps reduce infrastructure costs, especially during weekends or off-hours when the Development/QA environments are less active than regular working hours. With this add-on, we can autoscale arbitrary HTTP servers based on the volume of incoming traffic, even down to zero replicas.
Understanding and installing the KEDA HTTP add-on
The KEDA HTTP Add-on is built on top of the KEDA core and utilizes an interceptor and external scaler to scale the target HTTP server. The components of the add-on include:
a) Operator: This operator listens/watches for a resource called HTTPscaledObject and creates and configures interceptors and scalers allowing your existing Deployment to autoscale based on incoming HTTP traffic.
b) External scaler: This component communicates scaling-related metrics to KEDA. The External scaler constantly pings the interceptor to get pending HTTP queue metrics. It transforms these data and sends them directly down to KEDA, which then makes a scaling decision.
c) Interceptor: It accepts the HTTP request, and forwards the HTTP requests to the target application. Sends the pending HTTP request queue metrics to an external scaler and holds requests in a temporary request queue when there isn’t any Pod ready to serve the traffic.
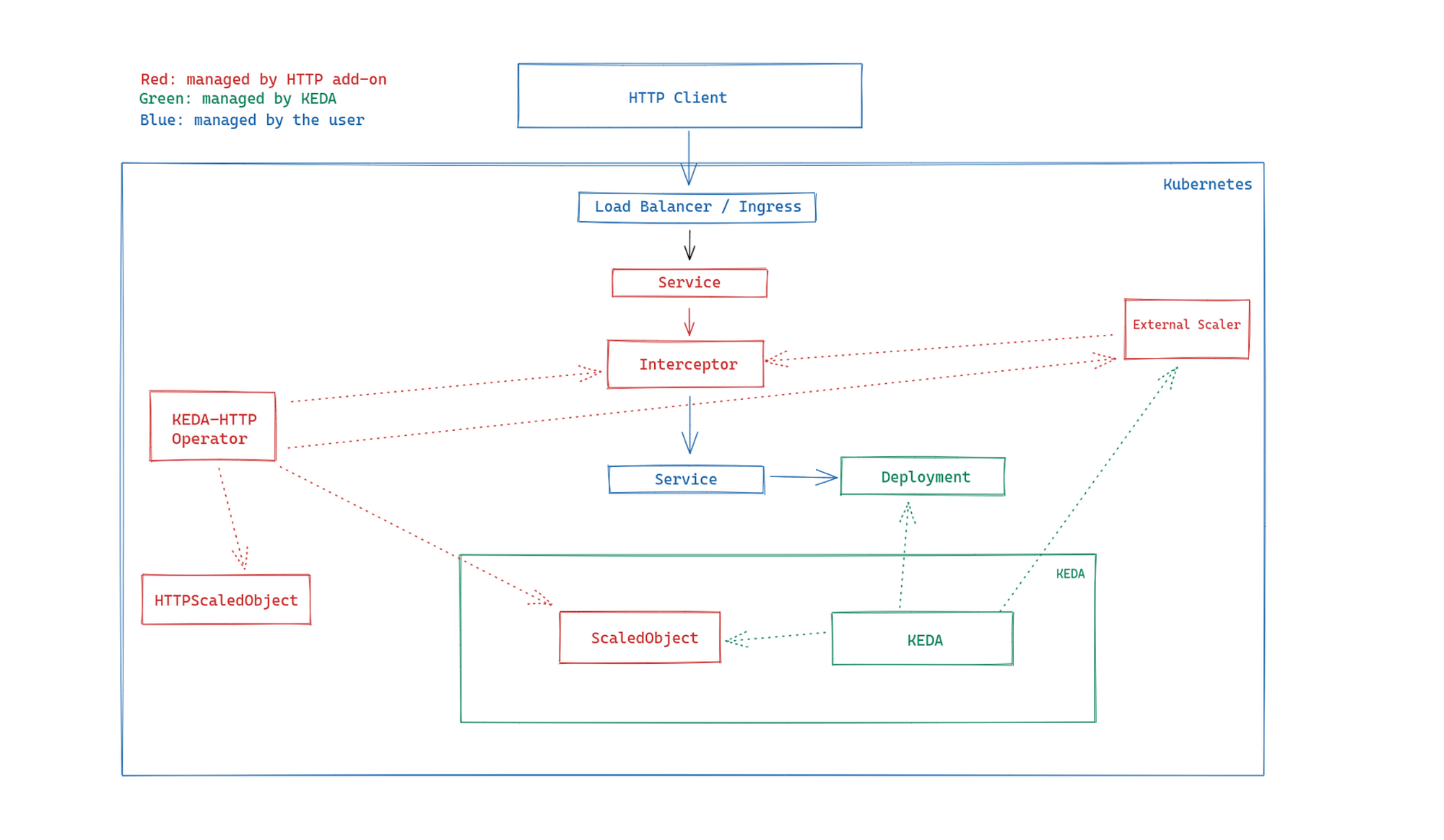
As you can see in the above image, the interceptor accepts the HTTP-based request, forwards them to the target application or holds them if the target application is scaled down to zero, and sends the pending HTTP request queue metrics to the external scaler. The external scaler gets the metrics data from the interceptor, transforms the data, and sends the data to KEDA, which makes scaling decisions.
The operator watches the HTTPScaledObject and configures the interceptor to forward the HTTP request to the target application.
Installation
Setting up KEDA and the KEDA HTTP add-on is a straightforward process. All you need is the Helm CLI to install the components.
helm repo add kedacore <https://kedacore.github.io/charts>
helm install keda kedacore/keda
helm install http-add-on kedacore/keda-add-ons-http
Once the installation is complete, you can start using the KEDA add-on by configuring your application and referencing it with HTTPScaledObject.
Installation with Devtron
For better visibility of the workloads, a dashboard always helps. Devtron comes with helm dashboard which can help you deploy any helm chart and observe the workloads from its user-intuitive dashboard. For more details about: The helm dashboard by Devtron.
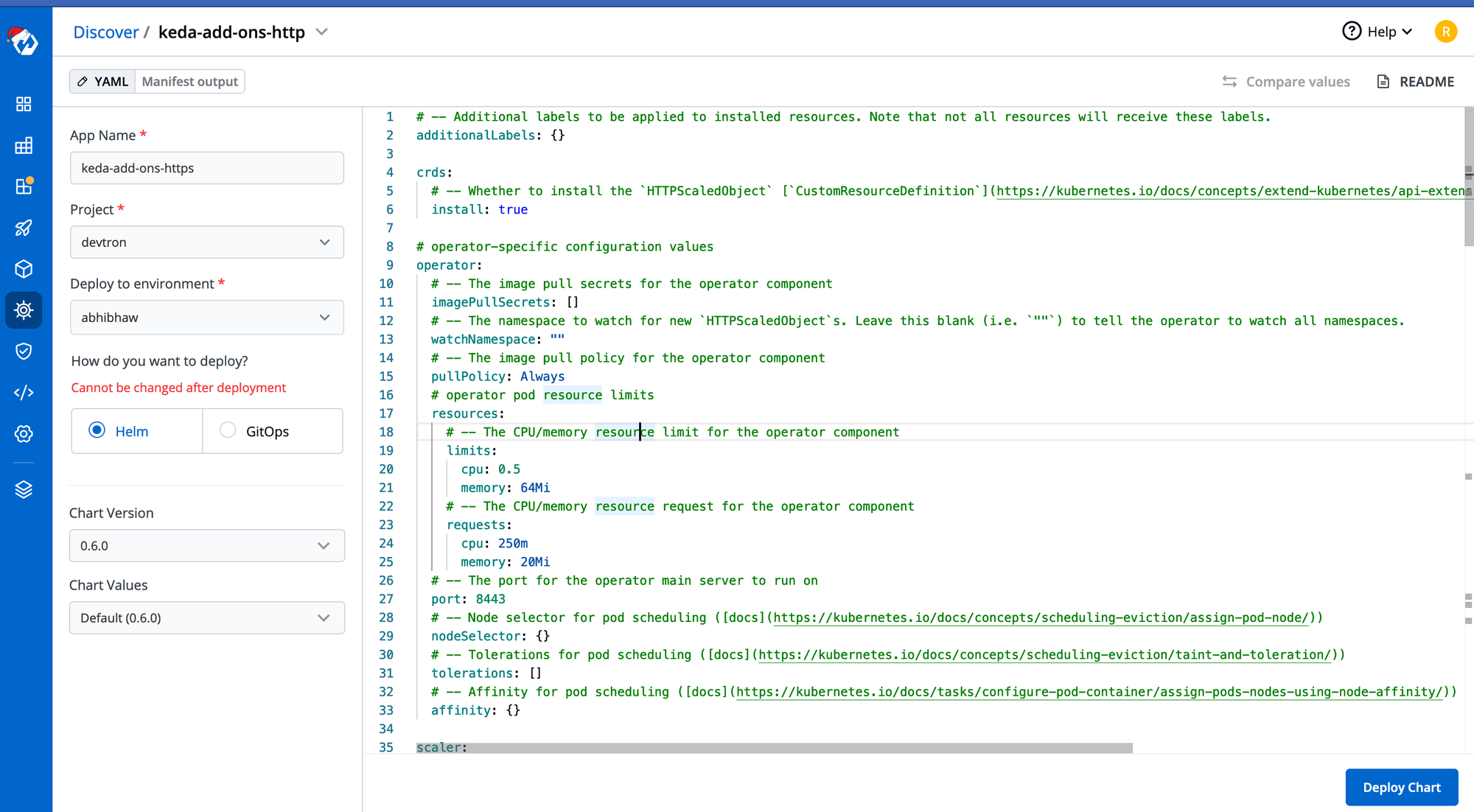
We can install the Keda-add-ons-http from the Devtron’s chart store, we need to search for keda-add-ons-http and provide the basic installation configuration like application name, environment where it needs to be deployed and the project name.
Please refer to the screenshot for the inputs.
After we configure and deploy the helm chart, let’s wait for the deployment to complete. As you can see in the below image, Devtron automatically grouped all the workloads deployed with this helm chart and it shows the real-time application health details. It makes it much easier to debug and observe the application’s health with such dashboards.
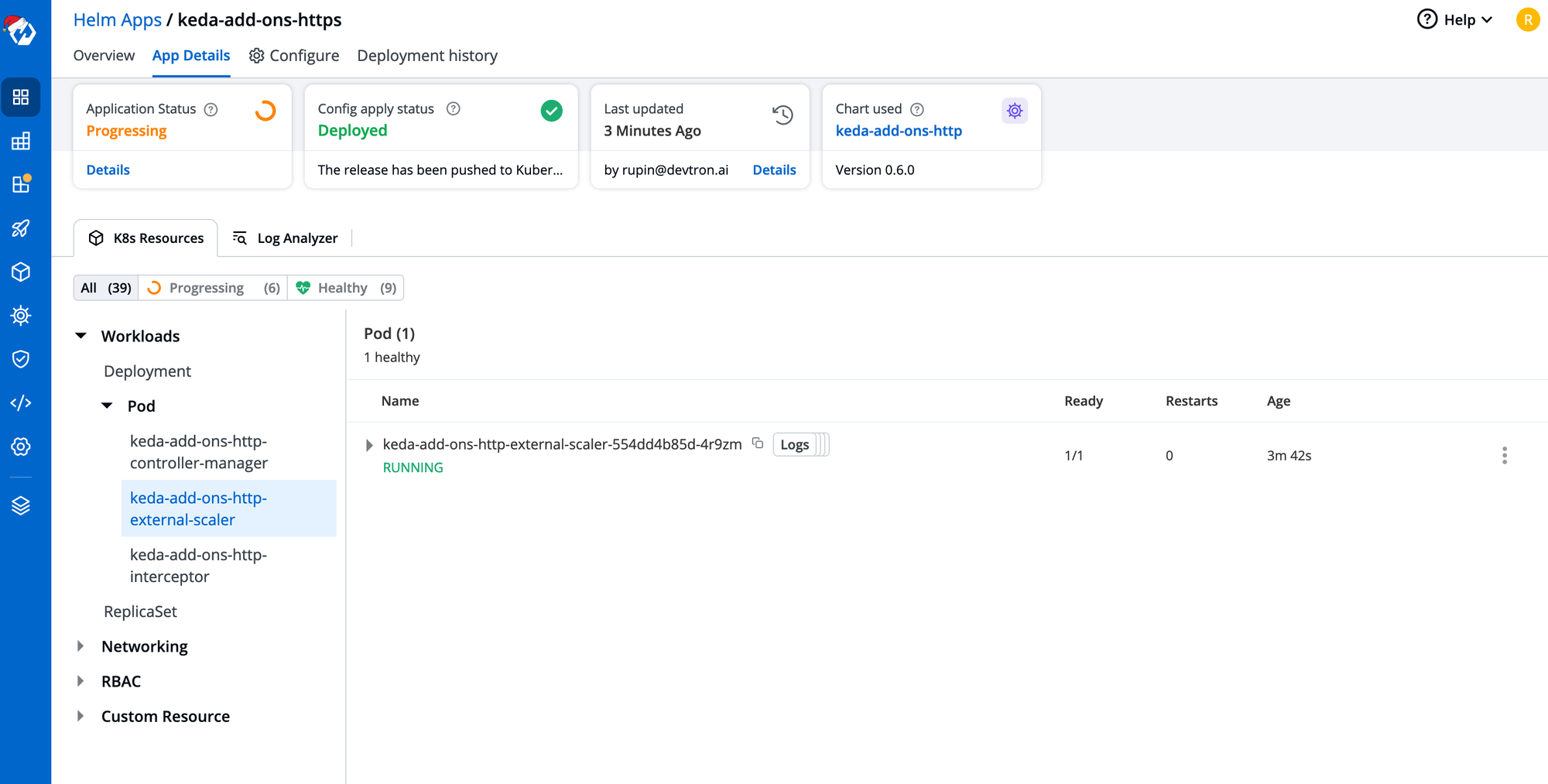
Now we can start using the KEDA add-on for scaling the application based on the HTTP Metrics.
Note: HTTPScaledObject only works with deployment ( in the current version )
Understanding the HTTPScaledObject
The installation includes a new CRD (Custom resource definition) called [HTTPScaledObject.http.keda.sh](<http://HTTPScaledObject.http.keda.sh>) - HTTPScaledObject. The resources allows to autoscale HTTP-based application and sets up the required internal components to deploy HTTP application and expose it internally or externally.
When an HTTPScaledObject is created, it performs the following tasks:
- Update an internal routing table that maps incoming HTTP hostnames to internal applications.
- Furnish this routing table information to interceptors so that they can properly route requests.
- Create a ScaledObject for the
Deploymentspecified in theHTTPScaledObjectresource.
Once the HTTPScaledObject and its related resources are created by operator, requests can be sent through the interceptor to scale the application. These requests are sent to keda-add-ons-http-interceptor-proxy . The interceptor then forwards the requests to the target application based on the request's host.
Here is an example manifest for the HTTPScaledObject:
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: xkcd
spec:
hosts:
- myhost.com
scaleTargetRef:
deployment: xkcd
service: xkcd
port: 8080
replicas:
min: 5
max: 10
scaledownPeriod: 300
targetPendingRequests: 100
The Keda Add-on routes the application to the target application based on the host specified in the HTTPScaledObject manifest.
Deploying the Sample Application and Live Manifest of HTTPScaledObject
Here are the deployment and service manifests. You can use Devtron’s generic-helm-chart to deploy any kind of Kubernetes manifests, or you can simply use kubectl to deploy the change in your Kubernetes cluster.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: scale-application-testing
name: scale-application
spec:
minReadySeconds: 60
progressDeadlineSeconds: 600
replicas: 1
selector:
matchLabels:
app: scale-application-testing
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: scale-application-testing
spec:
containers:
image: stefanprodan/podinfo
imagePullPolicy: IfNotPresent
name: scale-application
ports:
- containerPort: 9898
name: app
protocol: TCP
resources:
limits:
cpu: 100m
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
---
apiVersion: v1
kind: Service
metadata:
labels:
app: scale-application-testing
name: scale-application
spec:
ports:
- name: app
port: 80
protocol: TCP
targetPort: app
selector:
app: scale-application-testing
type: ClusterIP
---
apiVersion: v1
kind: Service
metadata:
name: scale-application-service-proxy
spec:
externalName: keda-add-ons-http-interceptor-proxy.keda.svc.cluster.local
sessionAffinity: None
type: ExternalName
Once the deployment and service are deployed, you can configure the HTTPScaledObject:
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: scale-application
spec:
hosts:
- scale-application-service-proxy
scaleTargetRef:
deployment: scale-application
service: scale-application
port: 80
replicas:
min: 0
max: 3
scaledownPeriod: 300
targetPendingRequests: 100
Upon creating the HTTPScaledObject, the target application is scaled down to 0 pods as no HTTP requests are passing through the interceptor proxy (keda-add-ons-http-interceptor-proxy). You can confirm this by running kubectl get pods.
We leverage the ExternalName service type to direct requests to the interceptor, which is keda-add-ons-http-interceptor-proxy. The request is routed through the service proxy, scale-application-service-proxy, and ultimately reaches the target application, scale-application.
To test this setup, you can use the following command:
curl -v <http://scale-application-service-proxy>
When you send a curl request to http://scale-application-service-proxy, the request goes through the interceptor, which then routes it to the correct application.
After making the request, you can check the status of the pods by running kubectl get pods. You should see that the pods have been created as expected.
Now in this current setup we can face a problem in upgrading the application when the current application is already scaled down due to no HTTP request. To resolve the problem statement we can trigger a job which will run post deployment of the application, the job will hit a curl request to the targeted application for scaling up the application after the deployment.
A sample manifest of the job is:
apiVersion: batch/v1
kind: Job
metadata:
name: admin-service-curl
annotations:
helm.sh/hook: post-install, post-upgrade
spec:
ttlSecondsAfterFinished: 100
backoffLimit: 4
template:
spec:
restartPolicy: Never
containers:
- name: curl-admin-service
image: "@{{CURL_IMAGE}}"
command:
- /bin/sh
- -c
- curl -v <http://scale-application-service-proxy>
Conclusion
Scaling HTTP-based applications with KEDA and the HTTP Add-on brings significant benefits to Kubernetes environments. By dynamically adjusting the number of replicas based on incoming HTTP traffic, we can optimize resource utilization, improve application performance, and reduce costs.
Incorporating KEDA and the HTTP Add-on into your Kubernetes deployment not only enhances the scalability of your HTTP-based applications but also ensures efficient resource allocation. By scaling up or down based on real-time traffic demands, you can provide a seamless user experience while optimizing the utilization of your infrastructure.
KEDA and the HTTP Add-on empower developers and operators to achieve dynamic and efficient scaling of HTTP applications in Kubernetes, delivering enhanced performance, cost optimization, and a responsive user experience. Explore the potential of KEDA and leverage the HTTP Add-on to unlock the full scalability potential of your applications.
Not only with add-ons, but KEDA is also efficient enough to autoscale based on ALB metrics, based on Kafka Lag, Prometheus metrics and lots of other events and triggers.
Feel free join our community discord server and let us if you have any questions. We would be more than happy to help you.







