

In dynamic Kubernetes environments, monitoring and alerting are crucial aspects of maintaining reliable Kubernetes clusters. The Kubernetes administrators, DevOps, and SREs have to rely on these metrics and alerts as they act as they look into their Kubernetes environments. Open-source tools like Prometheus excel at collecting the metrics from Kubernetes clusters and the Prometheus Alertmanager transforms these raw metrics into actionable alerts and notifications. For the Kubernetes administrators, DevOps, and SREs configuring the Prometheus Alertmanager is a key step to build a robust incident response while ensuring critical issues never go unnoticed. In this blog, we'll focus on setting up alerts for two critical scenarios: production application restarts and resource throttles.
Why Alerts in Kubernetes?
Kubernetes clusters and their workloads are essentially black boxes running our applications in highly dynamic and complex environments. While tools like Prometheus effectively monitor these environments and provide actionable insights through Grafana dashboards, the challenge lies in continuous observation. It's impractical and inefficient for teams to constantly watch these dashboards for potential issues. This is where alerts and notifications become crucial. Without an automated alerting system, critical issues could go unnoticed until they cause significant disruption, as teams can't maintain 24/7 manual monitoring of metrics dashboards. Alerts transform passive monitoring into active incident response, enabling teams to address issues before they impact service reliability. Some of the major incidents where we need a proper alert system in Kubernetes can be:
Production Application Restarts
Unexpected restarts can indicate issues with your application, such as crashes, resource constraints, or configuration problems. Monitoring these restarts helps you maintain high availability and quickly respond to potential issues.
Throttles
Throttling occurs when your application hits resource limits, potentially affecting performance and user experience. Alerts for throttles can help you identify and address resource bottlenecks before they become critical.
What is Prometheus Alertmanager?
Prometheus Alertmanager is part of an open-source project i.e. Prometheus, a monitoring solution. The Prometheus Alertmanager is a crucial part that works alongside the Prometheus monitoring system to handle and route the alerts generated. You can think of it as a notification system that handles alerts generated by the Prometheus server in a Kubernetes environment. Prometheus Alertmanager takes care of:
Alert Handling
- Receives alerts from one or multiple Prometheus servers
- Deduplicates alerts to avoid notification spam
- Groups related alerts together (like multiple server failures in the same region)
- Silence alerts during planned maintenance periods
Notification Management
- Routes alerts to the right teams based on predefined rules
- Supports multiple notification channels like:
- Slack
- PagerDuty
- OpsGenie
- Discord
- Custom Webhooks
How Prometheus Alertmanager works?
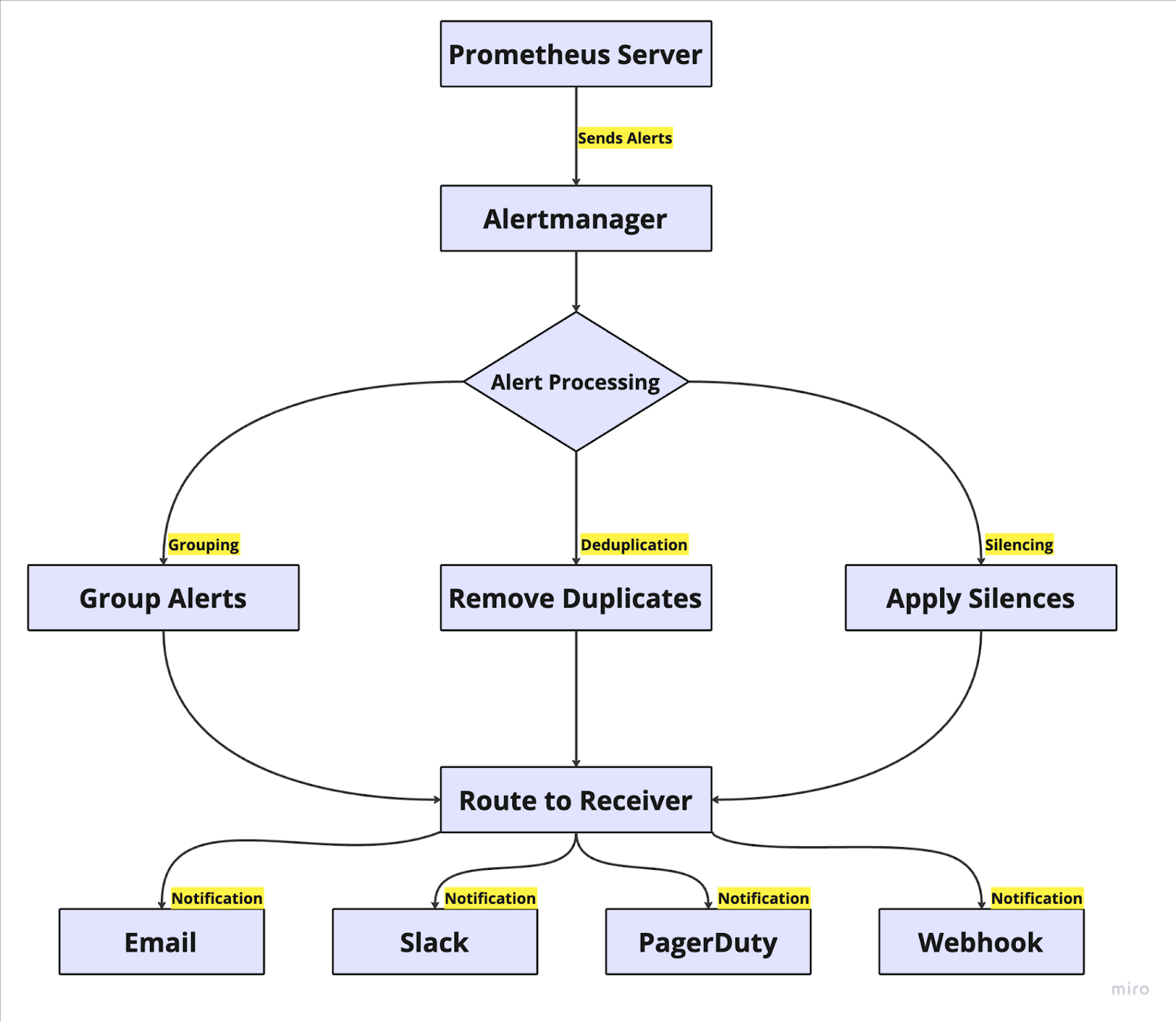
Key components of Prometheus Alertmanager:
- Prometheus Server: This is the main Prometheus server which collects key metrics of Kubernetes infrastructure.
- Alertmanager: A component of The Prometheus ecosystem that handles the alerts and notifications.
- Grouping: A mechanism that combines multiple related alerts (like multiple pod failures in the same namespace) into a single notification to reduce alert noise.
- Deduplication: A process that automatically identifies and removes duplicate alerts from multiple Prometheus servers to prevent notification spam and ensure each unique issue is reported only once.
- Silencing: A feature that temporarily suppresses specific alerts during planned maintenance windows.
- Route to Receiver: A configuration system that directs specific alerts to appropriate notification channels (receivers).
How to Configure Prometheus Alertmanager in Kubernetes
Let’s dive deep into how we can set alerts for various incidents on our Kubernetes infrastructure.
High CPU Throttling
An alert condition that triggers when containers hit their CPU limits and face forced CPU restrictions, indicating your application is trying to use more processing power than allocated in your Kubernetes configuration. When throttling occurs, it directly impacts application performance and responsiveness.
Configuring alerts for High CPU Throttling ensures that your applications do not overconsume CPU resources, which can degrade performance.
- alert: NodeCPUUsage
expr: instance:node_cpu_utilisation:rate5m > 85
for: 2m
labels:
severity: critical
annotations:
summary: "{{ $labels.node }}: High CPU usage detected"
description: "`{{ $labels.node }}`:- CPU usage is above 85% (current value is: {{ $value | printf \"%.2f\" }}%)"
resolved_desc: "`{{ $labels.node }}`:- *RESOLVED*: CPU usage is within thresholds (current value is: {{ $value | printf \"%.2f\" }}%)"
High Memory Usage
These alerts are triggered when your Kubernetes pods are consuming memory close to their defined limits generally, it’s around 80-90% utilization.
The High Memory Usage alerts are vital because they anticipate situations like Out of Memory (OOM) that can cause application instability or service disruptions.
- alert: NodeMemoryUsage
expr: (100 * instance:node_memory_utilisation:ratio) > 85
for: 2m
labels:
severity: critical
annotations:
summary: "{{ $labels.node }}: High memory usage detected"
description: "{{ $labels.node }}: Memory usage is above 85% (current value is: {{ $value | printf \"%.2f\" }}%)"
resolved_desc: "{{ $labels.node }}: *RESOLVED*: Memory usage is within thresholds (current value is: {{ $value | printf \"%.2f\" }}%)"
Node Disk Usage
Monitors and alerts when a node's disk space consumption reaches critical thresholds across Kubernetes nodes and container storages.
Node disk usage alerts are critical because full disks can paralyze node operations, prevent new container creation, and stop log collection. Monitoring disk usage helps maintain node health by allowing teams to implement cleanup procedures, adjust retention policies, or add capacity before reaching critical levels that could force unplanned downtimes or service degradation.
- alert: NodeDiskUsage
expr: 100 - (100 * (node_filesystem_avail_bytes / node_filesystem_size_bytes)) > 85
for: 5m
labels:
severity: critical
annotations:
summary: "{{ $labels.node }}: High Disk Usage detected"
description: "{{ $labels.node }}: Disk usage is above 85% on {{ $labels.device }} (current value is: {{ $value | printf \"%.2f\" }}%)"
resolved_desc: "{{ $labels.node }}: *RESOLVED*: Disk usage is within thresholds on {{ $labels.device }} (current value is: {{ $value | printf \"%.2f\" }}%)"
Container High Memory Usage
Monitoring high memory usage in containers is essential to ensure optimal performance across your cluster. Setting up alerts that notify you when memory consumption consistently exceeds defined thresholds over a specified duration can help you identify and address potential issues promptly. Excessive memory usage by a single container can lead to degraded performance for the entire cluster, resulting in application slowdowns or crashes.
- alert: ContainerMemoryUsageHigh
expr: (sum(container_memory_working_set_bytes{namespace=~".*"}) BY (instance, name, pod, namespace) /
sum(container_spec_memory_limit_bytes{namespace=~".*"} > 0) BY (instance, name, pod, namespace) * 100) > 80
for: 5m
labels:
severity: critical
annotations:
description: '{{ $value | printf "%.2f" }}% High memory usage in namespace {{$labels.namespace }} for pod {{ $labels.pod }}.'
resolved_desc: '*RESOLVED* : Memory usage is normal now (current value is: {{ $value | printf "%.2f" }})'
summary: Container Memory Usage is too high.
Pod Restarts and OOMKilled
Monitors pod lifecycle events focusing on abnormal terminations, tracking both frequent restarts and Out-of-memory (OOM) kills in your Kubernetes cluster.
These alerts are crucial operational indicators as they signal underlying problems that can severely impact service reliability. Frequent pod restarts often reveal application stability issues, improper resource limits, or configuration problems that could affect user experience. OOM kills are particularly critical as they represent hard failures where pods are forcibly terminated, potentially losing in-flight transactions or causing service outages.
- alert: Too many Container restarts
annotations:
summary: Container named {{ $labels.container }} in {{ $labels.pod }} in {{ $labels.namespace }} was restarted
description: "Namespace: {{$labels.namespace}}\nPod name: {{$labels.pod}}\nContainer name: {{$labels.container}}\n"
expr: sum(increase(kube_pod_container_status_restarts_total{pod_template_hash=""}[15m])) by (pod,namespace,container) > 5
for: 0m
labels:
severity: critical
app: "{{ $labels.pod }}"
---
- alert: PodOOMKilled
annotations:
summary: Pod named {{ $labels.pod }} in {{ $labels.namespace }} was OOMKilled
description: "Namespace: {{$labels.namespace}}\nPod name: {{$labels.pod}}\nContainer name: {{$labels.container}}\n"
expr: (kube_pod_container_status_last_terminated_reason{reason="OOMKilled"} > 0) and on (container)(increase(kube_pod_container_status_restarts_total[24h]) > 0)
for: 0m
labels:
severity: critical
app: "{{ $labels.pod }}"
CPU Throttle High Override
A specialized alert configuration that creates exceptions for specific high-priority workloads to bypass standard CPU throttling restrictions. This override mechanism monitors critical containers marked as essential services, allowing them to exceed normal CPU limits temporarily.
CPU throttle overrides are essential for maintaining service prioritization in production environments.
- alert: CPUThrottlingHigh-override
annotations:
summary: CPUThrottlingHigh for container {{ $labels.container }} in pod {{ $labels.pod }}.
message: "{{ $value | humanizePercentage }} throttling of CPU in namespace {{ $labels.namespace }} for container {{ $labels.container }} in pod {{ $labels.pod }}."
expr: >-
sum(increase(container_cpu_cfs_throttled_periods_total{container!="",}[5m])) by (container, pod, namespace)
/
sum(increase(container_cpu_cfs_periods_total{}[5m])) by (container, pod, namespace)
> ( 50 / 100 )
for: 20m
labels:
severity: critical
---
- alert: 100%-CPUThrottling-Critical
annotations:
summary: 100% Throttling of CPU for container {{ $labels.container }} in pod {{ $labels.pod }}.
message: "{{ $value | humanizePercentage }} throttling of CPU in namespace {{ $labels.namespace }} for container {{ $labels.container }} in pod {{ $labels.pod }}."
expr: >-
sum(increase(container_cpu_cfs_throttled_periods_total{container!="",}[5m])) by (container, pod, namespace)
/
sum(increase(container_cpu_cfs_periods_total{}[5m])) by (container, pod, namespace)
> ( 95 / 100 )
for: 2m
labels:
severity: critical
Kubepod is Not Ready
Monitors the readiness state of pods in your Kubernetes cluster, triggering when pods fail their defined readiness probes or remain in a not-ready state beyond expected initialization times.
Pod readiness alerts are fundamental to service reliability as they directly impact application availability and user experience. When pods aren't ready, Kubernetes removes them from service load balancing, potentially reducing system capacity and increasing the load on the remaining pods.
- alert: KubePodNotReady-override
expr: sum by(namespace, pod) (
max by(namespace, pod) (kube_pod_status_phase{job="kube-state-metrics",namespace=~".*",phase=~"Pending|Unknown", namespace=~".*"})
* on(namespace, pod) group_left(owner_kind)
topk by(namespace, pod) (1, max by(namespace, pod, owner_kind) (kube_pod_owner{owner_kind!="Job"}))
) > 0
for: 10m
labels:
severity: critical
team: infra
annotations:
description: Pod {{ $labels.namespace }}/{{ $labels.pod }} has been in a non-ready state for longer than 5 minutes.
summary: Pod has been in a non-ready state for more than 5 minutes.
PVC Warning and Critical Alert
Monitors the health and status of Persistent Volume Claims (PVCs) across your Kubernetes cluster, detecting multiple critical scenarios including storage capacity issues, binding failures, and mounting problems.
PVC alerts are vital for data-dependent applications since storage issues can cause severe service disruptions. When storage problems occur, they often lead to application crashes, data corruption, or complete service outages as pods can't access their required data. These alerts help prevent data loss scenarios by warning teams before volumes fill up.
- alert: KubePersistentVolumeFillingUp-warning
expr: (kubelet_volume_stats_used_bytes / kubelet_volume_stats_capacity_bytes) > 0.85
for: 10m
labels:
severity: warning
annotations:
description: The PersistentVolume claimed by {{ $labels.persistentvolumeclaim }} in Namespace {{ $labels.namespace }} is filled up more than 85%. Currently {{ $value | humanizePercentage }}.
summary: PersistentVolume {{ $labels.persistentvolumeclaim }} is filling up.
---
- alert: KubePersistentVolumeFillingUp-critical
expr: (kubelet_volume_stats_used_bytes / kubelet_volume_stats_capacity_bytes) > 0.95
for: 1m
labels:
severity: critical
team: infra
annotations:
description: The PersistentVolume claimed by {{ $labels.persistentvolumeclaim }} in Namespace {{ $labels.namespace }} is filled up more than 95%. Currently {{ $value | humanizePercentage }}.
summary: PersistentVolume {{ $labels.persistentvolumeclaim }} is filling up.
Container is Not Ready
Monitors container health status by tracking readiness probe responses, triggering when containers fail their configured health checks over a specified time period. The alert activates when containers can't pass their readiness criteria.
Container readiness alerts are crucial for maintaining service reliability since they detect problems before they impact user traffic.
- alert: KubeContainerWaiting-override
annotations:
summary: Container {{ $labels.container }} is waiting for more than an hour.
message: Pod {{ $labels.namespace }}/{{ $labels.pod }} container {{ $labels.container }} has been in waiting state for longer than 1 hour.
expr: sum by (namespace, pod, container) (
kube_pod_container_status_waiting_reason{job="kube-state-metrics", namespace=~".*"}
) > 0
for: 1h
labels:
severity: critical
HPA Replica Mismatch
Monitors the discrepancy between desired and actual pod counts managed by the Horizontal Pod Autoscaler, triggering when the cluster fails to maintain the targeted pod scaling state.
HPA mismatch alerts are critical for maintaining application performance and resource efficiency. When the actual pod count doesn't match HPA targets, it often signals deeper problems like insufficient cluster resources, reaching quota limits, or issues with metric collection that prevent proper autoscaling.
- alert: KubeHpaReplicasMismatch-override
annotations:
summary: HPA {{ $labels.hpa }} has not matched the desired no. of replicas for more than 15 mins.
message: HPA {{ $labels.namespace }}/{{ $labels.hpa }} has not matched the desired number of replicas for longer than 15 minutes.
expr: >-
(kube_hpa_status_desired_replicas{job="kube-state-metrics", namespace=~".*"}
!=
kube_hpa_status_current_replicas{job="kube-state-metrics", namespace=~".*"})
and
changes(kube_hpa_status_current_replicas[15m]) == 0
for: 15m
labels:
severity: critical
Job Failed Alert
Monitors the completion status of Kubernetes jobs, triggering when jobs fail to reach successful completion within their defined parameters or experience repeated failures. The alert activates when jobs terminate with non-zero exit codes, exceed their backoff limits, or fail to complete within their expected timeframe
Job failure alerts are essential for maintaining reliable batch processing and scheduled tasks in your cluster. When jobs fail, it often indicates data processing errors, resource constraints, or configuration issues that could impact critical business operations like data backups, report generation, or system maintenance tasks.
- alert: KubeJobFailed-override
annotations:
summary: Job {{ $labels.job_name }} has failed to complete success within activeDeadlineSeconds.
message: Job {{ $labels.namespace }}/{{ $labels.job_name }} failed to complete.
expr: increase(kube_job_status_failed{job="kube-state-metrics", namespace=~".*"}[1h]) > 0
for: 0m
labels:
severity: critical
Routing Alerts
Now that in the above section, we have configured Alerts for Kubernetes environments, let’s set up receivers. For that, we need to configure routing rules to ensure alerts are sent to the appropriate receivers.
Official Doc-: https://prometheus.io/docs/alerting/latest/configuration/#route-related-settings
alertmanager:
config:
route:
routes:
- match:
team: devtron
receiver: dev-team-discord
Configuring Receivers
Alertmanager receivers act as the crucial bridge between detecting issues and notifying the right teams. These receivers define the endpoints where your alerts will be delivered, allowing you to transform raw alert data into actionable notifications. Whether you need to wake up an on-call engineer through PagerDuty, notify your team via Slack, or send detailed reports via email, receivers provide the flexibility to handle various notification scenarios
Official Doc-: https://prometheus.io/docs/alerting/latest/configuration/#general-receiver-related-settings
Slack Receiver / Discord Receiver
alertmanager:
config:
Receivers:
- name: null
- name: dev-team-watchdog
discord_configs:
- webhook_url: https://discord.com/api/webhooks/<webhook>
send_resolved: true
title: '[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .CommonLabels.alertname }}'
Email Receiver
receivers:
- name: 'email-notifications'
email_configs:
- to: 'oncall@yourcompany.com'
from: 'alertmanager@yourcompany.com'
smarthost: 'smtp.yourcompany.com:587'
auth_username: 'alertmanager@yourcompany.com'
auth_identity: 'alertmanager@yourcompany.com'
auth_password: 'your-smtp-password'
Testing Your Alerts
Once you've set up your alert rules and receivers, it's relevant to test them to ensure they're working as expected. Here are a few ways to test your alerts:
- Simulate alert conditions: Temporarily modify your alert rules to trigger based on current conditions.
- Use Prometheus's API: Send test alerts directly through the Prometheus API.
- Alertmanager's web UI: Use the Alertmanager web interface to view and manage active alerts.
Conclusion
Setting up basic alerts for your Kubernetes monitoring stack is a key step in maintaining the reliability and performance of your applications. By configuring alerts for issues like application restarts and CPU throttling, you can proactively identify and address potential problems before they affect your users. Keep in mind that alerting is an evolving process. As you gain deeper insights into your application's behavior and performance patterns, you’ll want to fine-tune your alert rules and add new ones to address other critical scenarios.





