In the fast-paced landscape of the software industry, Kubernetes has become a de facto standard for deploying, scaling, and managing the lifecycle of containerized applications. For multiple organizations Kubernetes has been a powerhouse for their services, promising high availability, ease of scaling, and flexibility. But as the saying goes, With great power comes great responsibility. Maintaining a Kubernetes infrastructure is the real challenge, where hundreds and thousands of nodes are spinning across multiple Kubernetes clusters and regions. When something breaks in some of these nodes, fixing even a small issue in these multiple nodes becomes a nightmare for developers/DevOps teams. Even if the fixes are small and take something like a few minutes teams are required to go through the complexities of Kubernetes. Even if you have teams of experts who can quickly navigate through the complexities and fix things, it gets tedious and time-consuming at scale, also adding up the risk of some misconfigurations as things are being done manually as it’s been said Anything that can go wrong will go wrong.
What if we have something that automatically traces the issue and fixes it without any manual intervention, just like most of the things that we have already configured to be executed automatically? For some common issues of Kubernetes, Devtron already has something called Resource Watcher, which listens to the cluster events, and if any issue is detected it automatically remediates the issue by itself.
In this blog, we will talk about Kured a CNCF Sandbox project l that can help you keep your Kubernetes nodes up to date by performing auto reboots after applying the security patches or getting Kernel-level updates.
Need of Self-Healing in Kubernetes
Before deep diving into the topic let’s discuss, do we need self-healing capabilities for our Kubernetes infrastructure. While running our services over Kubernetes there have been times when we all faced major or minor issues on the production cluster. If the issue is major something like insufficient ip addresses in cluster , for such issues manual troubleshooting can be the best way to deal. But some of the Kubernetes common issues arise frequently like OOM Killed, CrashLoopBackOff, ImagePullBackOff, DiskPressure, Node in NotReady State etc. These are some issues that require minor fixes, manually applying these fixes on the production cluster becomes a tedious and time-consuming process.
Another reason for the implementation of self-healing for our Kubernetes cluster is Kubernetes complexities and security concerns. Manual troubleshooting of Kubernetes issues involves a high level of complexity for developers. Navigating through complexities multiple times and fixing multiple issues involves a high risk of misconfiguration. Any small level of misconfiguration can bring your whole system down causing an unplanned downtime for users and impacting the business.
The Pain of Manually Rebooting Nodes
Imagine you are managing production servers across multiple Kubernetes clusters with hundreds of nodes. While minor issues can often be resolved through manual troubleshooting or auto-remediation features, major fixes like security patches at the kernel level or OS updates require node reboots. This process can be complex and error-prone when done manually.
The traditional manual node reboot process involves several steps:
- Marking the node as un-schedulable (cordoning) to prevent new pod assignments
- Gracefully moving existing workloads to other nodes (draining)
- Performing maintenance work, such as rebooting.
If the manual process is followed there is a high chance that you may end up running into challenges like:
- Risk of Downtime: Human errors during the process may cause unexpected service interruptions.
- Scalability Hurdles: As your infrastructure grows, manually managing node reboots becomes increasingly difficult.
- Environment Inconsistencies: Manual processes may result in configuration drift across nodes.
- Time-Consuming: The step-by-step manual approach could be more efficient, especially when dealing with large-scale clusters.
Now that we have already done a long discussion on the problem, let’s look for some solution and find out a way out of this pain.
Kured
Kured, an open-source CNCF Sandbox project, addresses the challenge of manual node reboots in Kubernetes environments. Kured, short for Kubernetes Reboot Daemon, is a Kubernetes daemonset that performs safe automatic node reboots when the need to do so is indicated by the package management system of the underlying OS. It gets deployed on the Kubernetes cluster as a demonset which automates the reboot process, it safely reboots nodes after security patches, OS updates, or any fix that requires a reboot of a node.
Here's how Kured detects which node needs a reboot:
1. Monitoring for Reboot Signals: Kured continuously monitors the Kubernetes nodes for specific reboot signals, such as the presence of the /var/run/reboot-required file. This file is typically created by package managers or system update processes when a reboot is required.
Another way to pass a reboot signal is configuring a window, Kured allows you to define a specific time window to perform the reboots. Setting up a specific time window to perform the safe reboots reduces unwanted downtimes.
One more way to detect the node that needs a reboot is by executing the reboot sentinel command. Once this command is executed on node Kured ignore the /var/run/reboot-required file and process with the reboot process according to the reboot sentinel command.
2. Node Locking: To ensure that Kured only reboots one node at a time, it uses a distributed lock mechanism. This lock is acquired before initiating the reboot process, preventing concurrent reboots and maintaining cluster availability.
Once Kured has detected which node requires a reboot and locked the node for the reboot process it starts with the safe reboot process of a node.
Features of Kured
Automated node reboots:
Kured automates the process of rebooting Kubernetes nodes when necessary, typically after system updates or security patches are applied.
Safe reboots:
Kured ensures that node reboots are performed safely by:
- Cordoning the node to prevent new pods from being scheduled.
- Draining existing pods to other nodes.
- Waiting for pods to terminate gracefully.
- Rebooting the node only when it's safe to do so.
Scheduled reboots:
Kured allows for scheduled reboots, enabling administrators to define specific time windows when reboots are allowed. This helps minimize disruption to cluster operations.
Benefits of Kured
Operational Efficiency
Kured automates the critical process of node reboots, which would otherwise require manual processes that are tedious and error-prone. The automation by Kured ensures that nodes are rebooted in a controlled, predictable manner, minimizing potential downtime and service interruptions. By handling the complexities of cordoning nodes, draining workloads, and timing reboots, Kured frees up valuable time for operations teams. This allows them to focus on more strategic tasks and innovations rather than managing routine maintenance. Additionally, the ability to schedule reboots during off-peak hours further reduces the impact on services, contributing to smoother overall cluster operations.
Improved Security
To maintain the security posture of our Kubernetes cluster we always need to ensure that our nodes in the cluster are running the most up-to-date with secure versions of system software. Kured's automated approach significantly helps us to plan the updates for nodes and reduces the pain of rebooting nodes post updates. Due to the automated approach and proper planning of updates, the window of vulnerability between when a security patch is released and when it's applied across the cluster reduces, resulting in strengthening the overall security of the Kubernetes cluster.
How Kured Works
Now that we have already seen how Kured helps us self-healing our Kubernetes nodes by securely rebooting them. Let’s see what the steps Kured takes once integrated into our Kubernetes cluster. The first thing is that Kured runs as a DaemonSet on every node of our Kubernetes cluster.
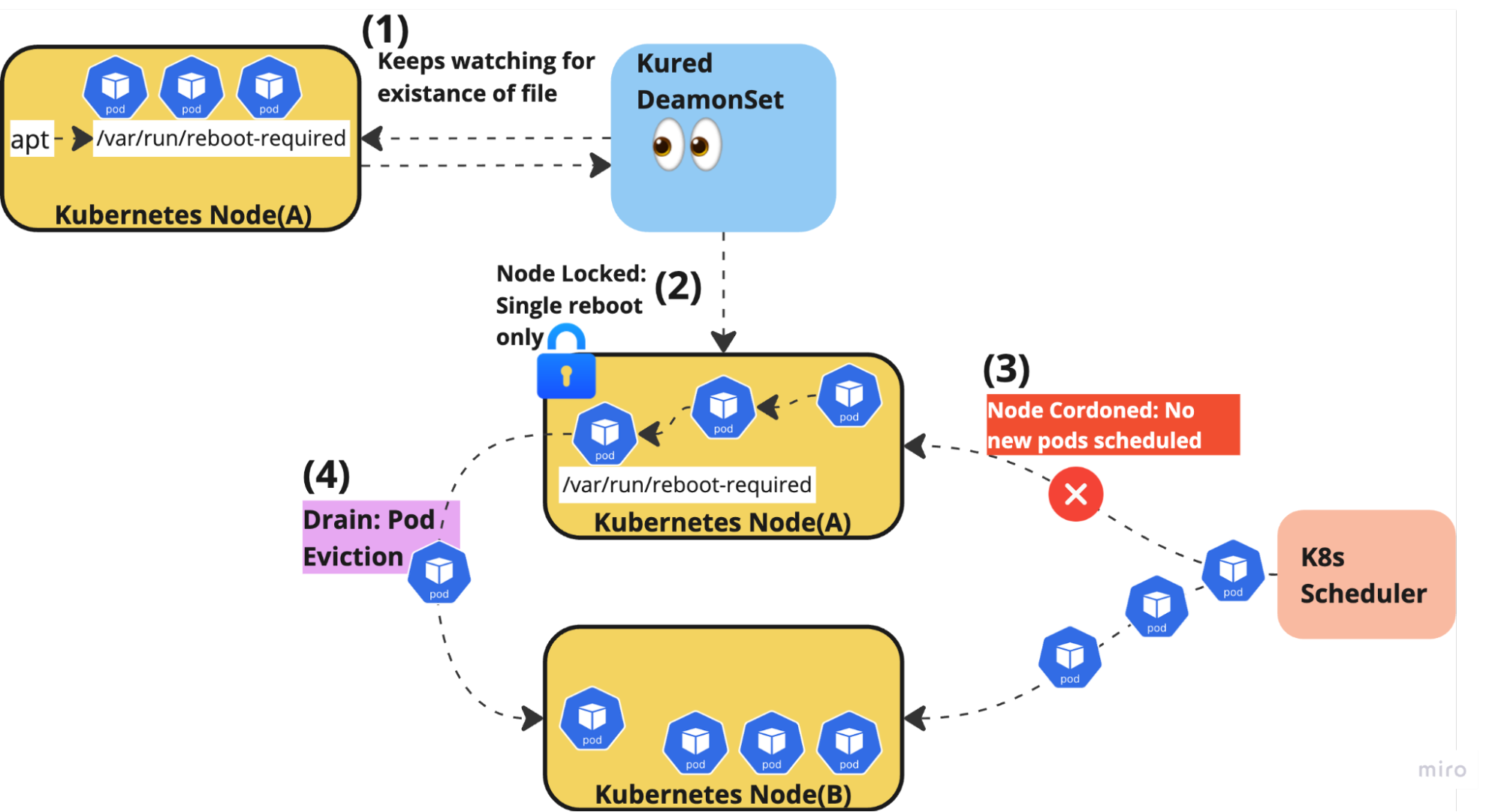
Once all pods are scheduled on another node, Kured triggers the reboot process for the specific node. Post reboot Kured releases the lock of the node and allows the pods to get scheduled on the same node.
Conclusion
In our Kubernetes production clusters, we often face some common issues of Kubernetes which require minimal troubleshooting, but as it's a production cluster, and that too with scale navigating through it to fix a small error is tedious and time-consuming. The Resource Watcher of Devtron comes to save our day when it comes to detecting and fixing common Kubernetes issues in large-scale production clusters securely and without any manual intervention. On the one hand, where Resource Watcher fixes issues for us, a tool like Kured comes in handy when it comes to rebooting nodes after fixes or updates. Kured emerges as a powerful solution to the challenges of maintaining and updating Kubernetes nodes at scale. Automating the reboot process significantly enhances operational efficiency and strengthens cluster security. Kured's ability to perform safe, scheduled reboots without manual intervention addresses key pain points in node management, including downtime risks, scalability issues, and potential misconfigurations. Using these both as a combination for Kubernetes clusters facilitates a Self-Healing of Kubernetes clusters.