If you are running micro-services these days there is a high probability that you're running it on a cloud provider like AWS, GCP, MS Azure, etc. The services of these cloud providers are powered by data centers, which typically comprise tens to thousands of interconnected servers and consume a substantial amount of electrical energy. It is estimated that data centers will use anywhere between 3% and 13% of global electricity by the year 2030 and henceforth will be responsible for a similar share of carbon emissions. This post will step through an example with a case study of how to use Kubernetes to minimize the amount of carbon in the atmosphere that your Organization's infrastructure is responsible for.
Carbon Footprint
What exactly is Carbon Footprint? It is the total amount of greenhouse gases (carbon dioxide, methane, etc) released into the atmosphere due to human interventions. Sounds familiar, isn’t it? We all have read about the different ways greenhouse gases get released into the atmosphere and the need to prevent it.
But why are we talking about it in a technical blog? And how can Kubernetes help to reduce your organization's Carbon footprint?
In the era of technology, everything is hosted on cloud servers, which are backed by massive data centers. In other words, we can say data centers are the brain of the internet. Right from the servers to storage blocks, everything is present in these Data Centers.
All the machines in the data centers require energy to operate, i.e, electricity. Irrespective of the source of generation, renewable or nonrenewable. According to a survey conducted by Aspen Global Change Institute, data centers account for being one of the direct contributors to climate change due to the release of greenhouse gases. According to an article by Energy Innovation, a large data center may contain tens of thousands of hardware and can use around 100 megawatts (MW) of electricity.
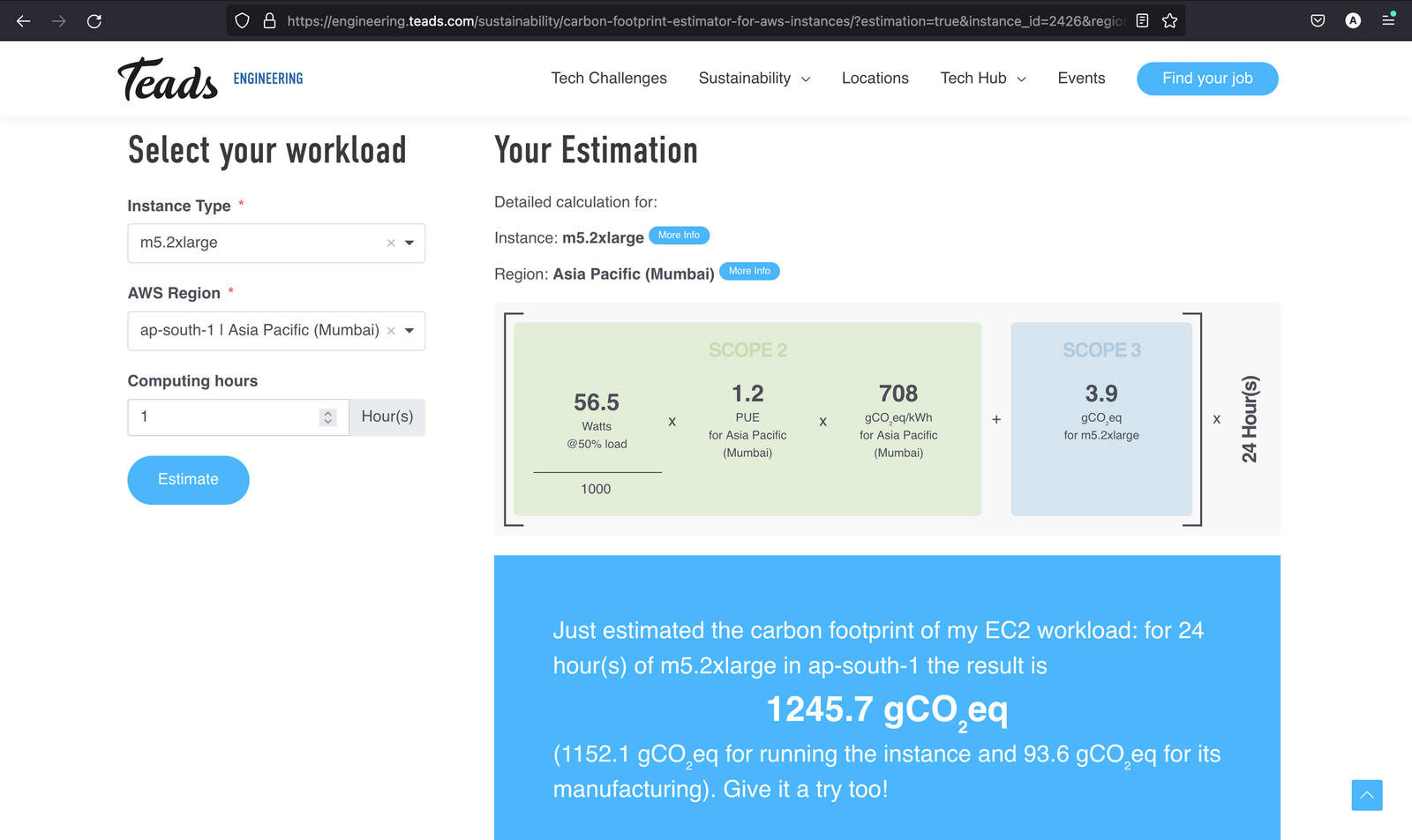
But again, how does using another technology i.e., Kubernetes can contribute to this? Before answering the above question let’s learn how to calculate the carbon footprint of a server that we usually create with a public cloud provider like AWS. In AWS, we create Instances of different sizes, computation power, storage capacity, etc as per our needs. Let’s calculate the carbon footprint emitted by initializing an instance of type - m5.2xlarge in the region - ap-south-1 which runs for 24 hours.
We can calculate the Carbon Footprint, by using the Carbon Footprint Estimator for AWS instances. As you can see in the below image, after giving the values, we can easily estimate the carbon footprint for the respective instance which is 1,245.7 gCO₂eq.
Factors Considered While Calculating
There are primarily two factors that contribute to carbon emissions in the Compute Resource carbon footprint analysis, which are discussed below -
- Carbon emissions related to running the instance, including the data center PUE
Carbon emissions from electricity consumed are the major source of carbon footprint in the Tech Industry. The AWS EC2 Carbon Footprint Dataset available is used for the calculation of Carbon emissions on the basis of how much wattage is used on various CPU consumption levels. - Carbon emissions related to manufacturing the underlying hardware
Carbon emissions from the manufacturing of hardware components are another major contributor when it comes to carbon footprint calculations within the scope of this study.
How Kubernetes can help?
Kubernetes is one of the most adopted technologies. As per the survey by Portworx, 68% of the companies have increased the usage of Kubernetes and IT automation and the adoption metrics are still increasing. For any application to be deployed over Kubernetes, we need to create a Kubernetes cluster that comprises any number of master and worker nodes. These are nothing but instances/servers which are being initialized where all the applications will be deployed. The number of nodes keeps on increasing as the load increases which eventually will contribute more and more to the Carbon footprint. But with the help of Kubernetes Autoscaling, we can lower the count of nodes i.e., reduce the number of instances created as per the requirements.
Let’s try to understand it with a use case.
A logistics company uses Kubernetes in its production to deploy all its micro-services. A single micro-service requires around 60 replicas which initialize around 20 instances of type - m5.2xlarge in region ap-south-1. If we calculate the Carbon Footprint of a single micro-service in 24 hours, it would be around 24,914 gCO₂eq. This is the amount of carbon footprint emitted just by a single micro-service for 24hrs, and there are thousands of micro-services in a well-versed organization that runs 24*7. Now if you are wondering how this can be reduced. Well, you are at the right place.
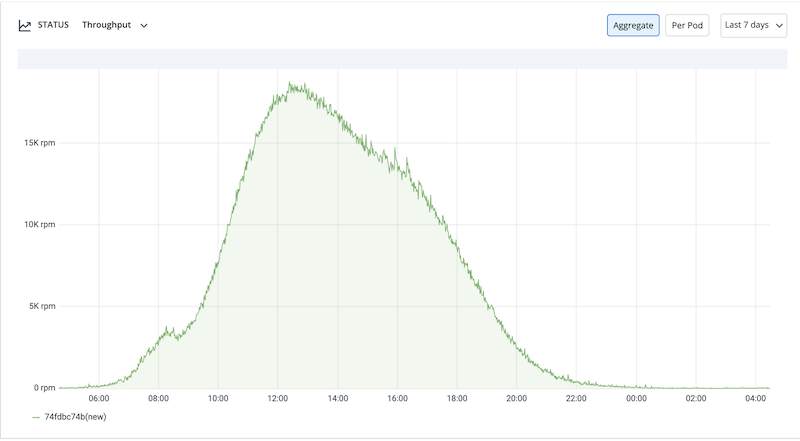
The maximum traffic that a logistic company's First mile / Last mile app experiences are during the day-time when the deliveries happen. Generally, from morning around 8:00 AM, there’s a steep increase in the traffic and it experiences its peak in afternoon hours. That's when it would have the most number of pod replicas and nodes/instances. Then post 8:00 PM the traffic decreases spontaneously. During the off hours, when the traffic decreases, the count of replicas also drops to 6 from an average of 60 for each micro-service, which requires only 2 nodes/instances. The micro-service uses throughput metrics based on horizontal pod autoscaling using Keda.
Now if we talk about the carbon emissions by 1 microservice after deploying it on Kubernetes paired with horizontal pod auto-scaling, it would drop to around
51.9 gCO₂eq x 2 (nodes) x 12 (hrs 8pm to 8am non-peak hours) + 51.9 gCO₂eq x 20 (nodes) x 12 (hrs 8am to 8pm peak traffic hours) = 13,701.6 gCO₂eq
51.9 gCO₂eq x 20 (nodes) x 24 (hrs no autoscaling) = 24,912 gCO₂eq
That's a whooping 11,211 gCO₂eq (45% reduction) in carbon emissions [1], and this is just by 1 micro-service in 24hrs. Which translates to 4092 KgCo2eq per year! For the reference of how much this is, a Boeing 747-400 releases about 90 KgCo2eq per hour of flight when it covers around 1000 Kms [2].
Now think of how much your organization is capable to reduce per year by migrating 1000s of micro-services on Kubernetes paired with efficient autoscaling.

Migrating to Kubernetes?
Kubernetes is the best container orchestration technology out there in the cloud native market but the learning curve for adopting Kubernetes is still a challenge for the organizations looking to migrate to Kubernetes. There are many Kubernetes-specific tools out there in the marketplace like ArgoCD, Flux for deployments, Prometheus and Grafana for monitoring, Argo workflows for creating parallel jobs, etc. Kubernetes space has so many options but they need to be configured separately, which again has its own complexities.
That's where Devtron helps you, Devtron stack configures and integrates all these tools that you would have to otherwise configure separately and lets you manage everything from one stunning dashboard. Devtron is an open-source software delivery workflow for Kubernetes. Devtron is trusted by thousands of users and giants like Delhivery, Bharatpe, Ather Energy, etc, and has a broad range of communities all across the globe. And the best thing is, it gives you a no-code Kubernetes deployment experience which means there's no need to write Kubernetes YAMLs at all.
[1] When compared to micro-services which are not configured to scale efficiently.
[2] https://catsr.vse.gmu.edu/SYST460/LectureNotes_AviationEmissions.pd
FAQ
How does Kubernetes help reduce carbon footprint in cloud infrastructure?
Kubernetes reduces cloud carbon emissions by autoscaling workloads based on demand, which limits unnecessary compute usage and energy waste.
What is organization carbon footprint?
An 'organisational carbon footprint' measures the amount of carbon dioxide and other greenhouse gases released into the atmosphere as a result of a company's activities.
How does Kubernetes autoscaling lower cloud costs and emissions?
Kubernetes autoscaling adds or removes resources as traffic changes, helping cut both cloud spend and environmental impact.
Fewer active instances during low traffic
Saves electricity and compute cost