

Kubernetes has become the most widely adopted container orchestrator and is used by many companies on a very large scale. Many companies even use multiple Kubernetes clusters to enable their applications to run flawlessly. Apart from its scalability, it also provides much value for automating deployments, managing containerized applications, and much more. To learn more about the capabilities of Kubernetes, check out the guide to Kubernetes.
Every application in Kubernetes runs as a container inside a pod. A small is the smallest unit in Kubernetes, a wrapper around containers. Within the pods, you may have a single, or multiple containers which share the network and storage assigned to the pod. However, there is a major concern when running applications within pods.
Pods by their very nature and ephemeral, which means that they are designed to be deleted after some time, or due to some event. For example, the pod may get deleted if it runs out of memory, or if the node goes down. When this happens, the application that runs in the pod will also be lost, and there will be a service disruption for end users.
To counter the above problem, Kubernetes has provided you with a few objects that make sure that the pod’s ephemeral nature does not disrupt the user experience. These objects are the Deployments and StatefulSets. Both are K8s objects for running pods, but they have some key differences. In this blog, we will be exploring both Deployments and StatefulSets in detail, and by the end, you will have a clear understanding of both objects and when to use which one.
Optimize your Kubernetes deployments by understanding the distinct roles of Deployments and StatefulSets, ensuring your applications run smoothly and efficiently.
Deployments
The deployment object in Kubernetes is generally used for deploying your applications onto Kubernetes. As we discussed above, pods can be deleted at any time, and as a result, your application will face downtime until the pod is recreated. Before we talk about deployments, let us understand ReplicaSets.
A ReplicaSet is a Kubernetes object that ensures that a pod is running at all times. If the pod is deleted for whatever reason the ReplicaSet ensures that the pod is recreated. However, the ReplicaSet does not ensure that the configuration of the Pod matches the configuration in the ReplicaSet. If you update the ReplicaSet while the pod is still running, it does not update the pod’s spec. To ensure that the pod reflects the updated configuration, you will need to delete the pod, and it will get recreated by ReplicaSet with the updated configuration.
A deployment takes the functionality of a ReplicaSet one step further. It ensures that the configuration of the Pod always matches the configuration defined in the deployment’s manifest file. You can also define a rollout strategy within the Deployment spec. To learn about what is a rollout strategy and its different types, please check out this blog. The deployment controller ensures that the pod and deployment’s configurations always match.
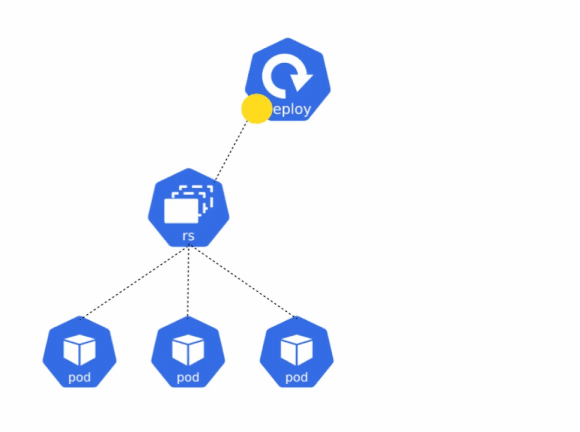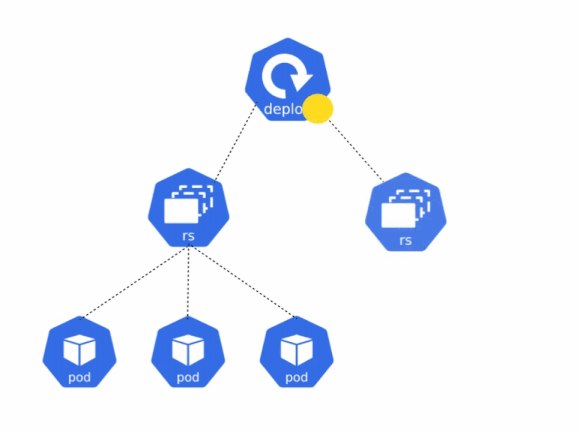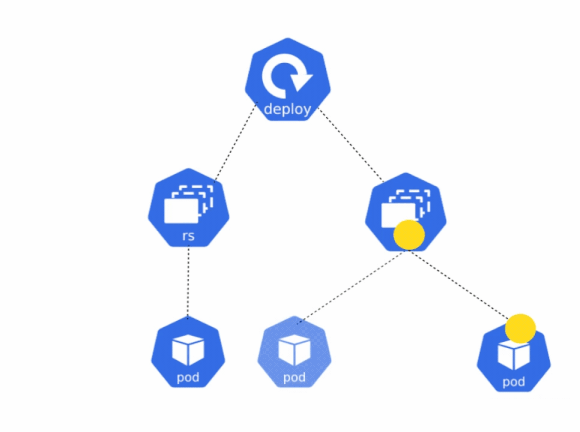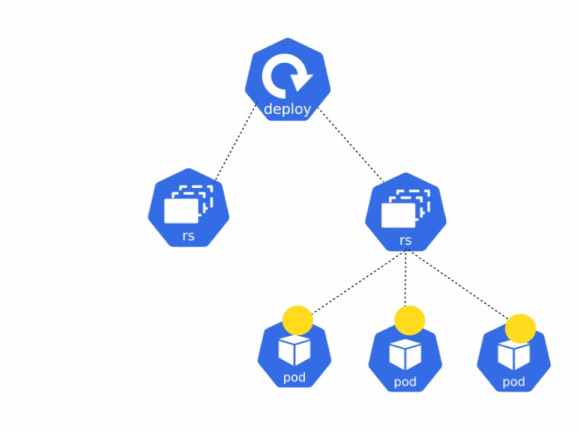
Deployments help you to achieve the following:
- To rollout ReplicaSet - It will create your pods in the background. You can check the status of the rollout to check if it is succeeded or not.
- Declare the new state of the pods - You can update the PodTemplateSpec of the deployment manifest. A new replicaset is created and the deployment moves the pods from old replicaset to the new one, at the controlled rate. Each new replicaset will now have the updated revision of the deployment.
- Rollback to earlier deployment revision - If due to some circumstance, the current state doesn’t turn out to be stable, then the deployment can be rolled back to earlier deployment revision.
What Deployment doesn’t provide?
- It doesn’t provide an identifier to pods.
- It doesn’t provide storage for pods, hence it is used for only stateless applications (the ones that don’t care which network is being used, and don’t need any permanent storage. For e.g., Web Servers such as Apache, Nginx, Tomcat).
Deployment Hands-on
Let’s understand the entire process and what happens behind the scenes with some hands-on examples.
First, let us create a deployment using a YAML file. In the below manifest, we are creating a deployment with 5 replicas i.e 5 pods of the same application, and we use the nginx image.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 5
selector:
matchLabels:
app: nginx
strategy: {}
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
Upon applying this file, there are a few things that will happen.
- The deployment will be created
- The deployment will create a ReplicaSet
- The ReplicaSet will create 5 pods
Note: In the below images, I have used an aliased kubectl to k. If you wish to set the name, you can run the below command
echo “alias k=kubectl” >> ~/.bashrc
source ~/.bashrc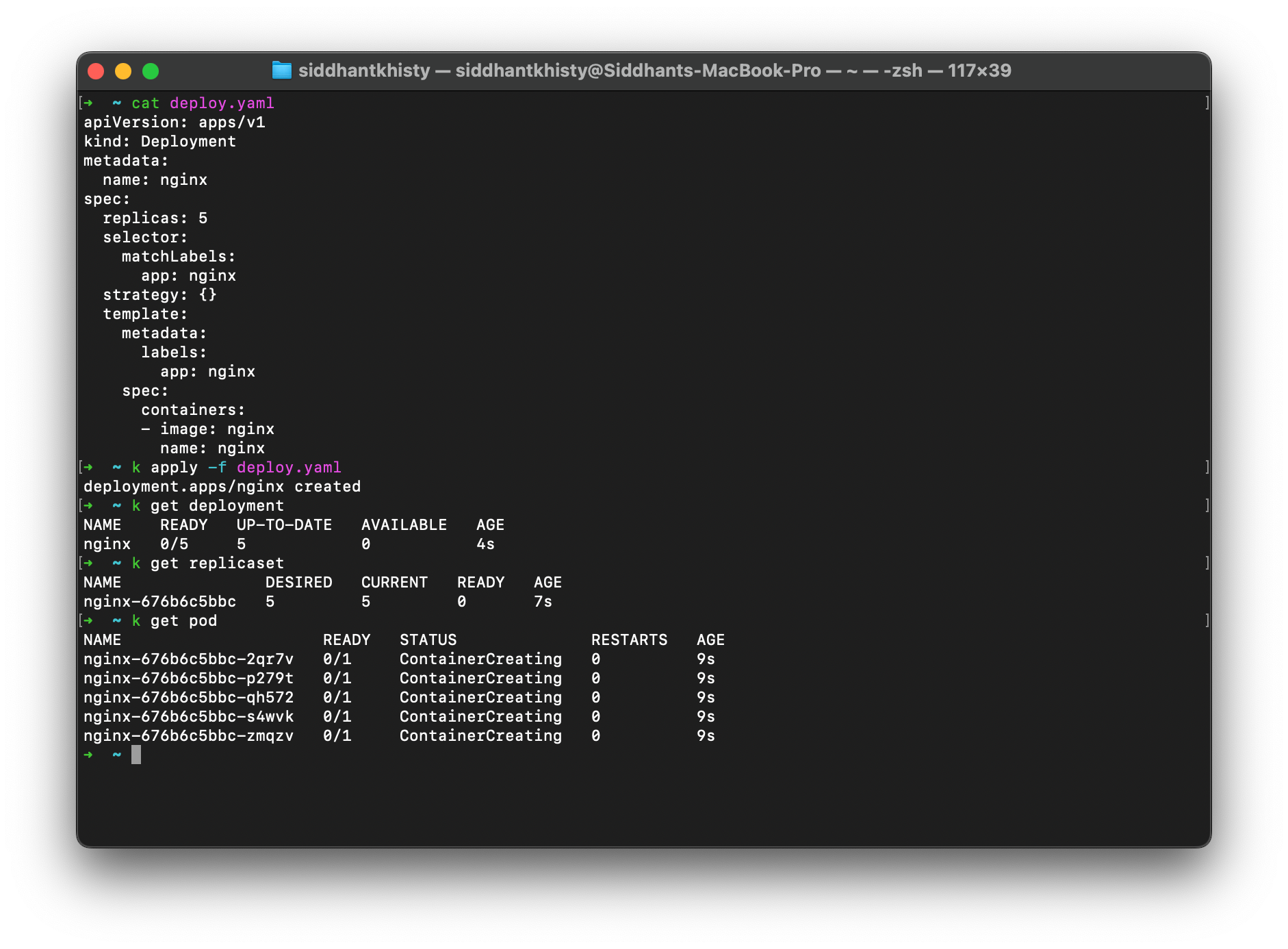
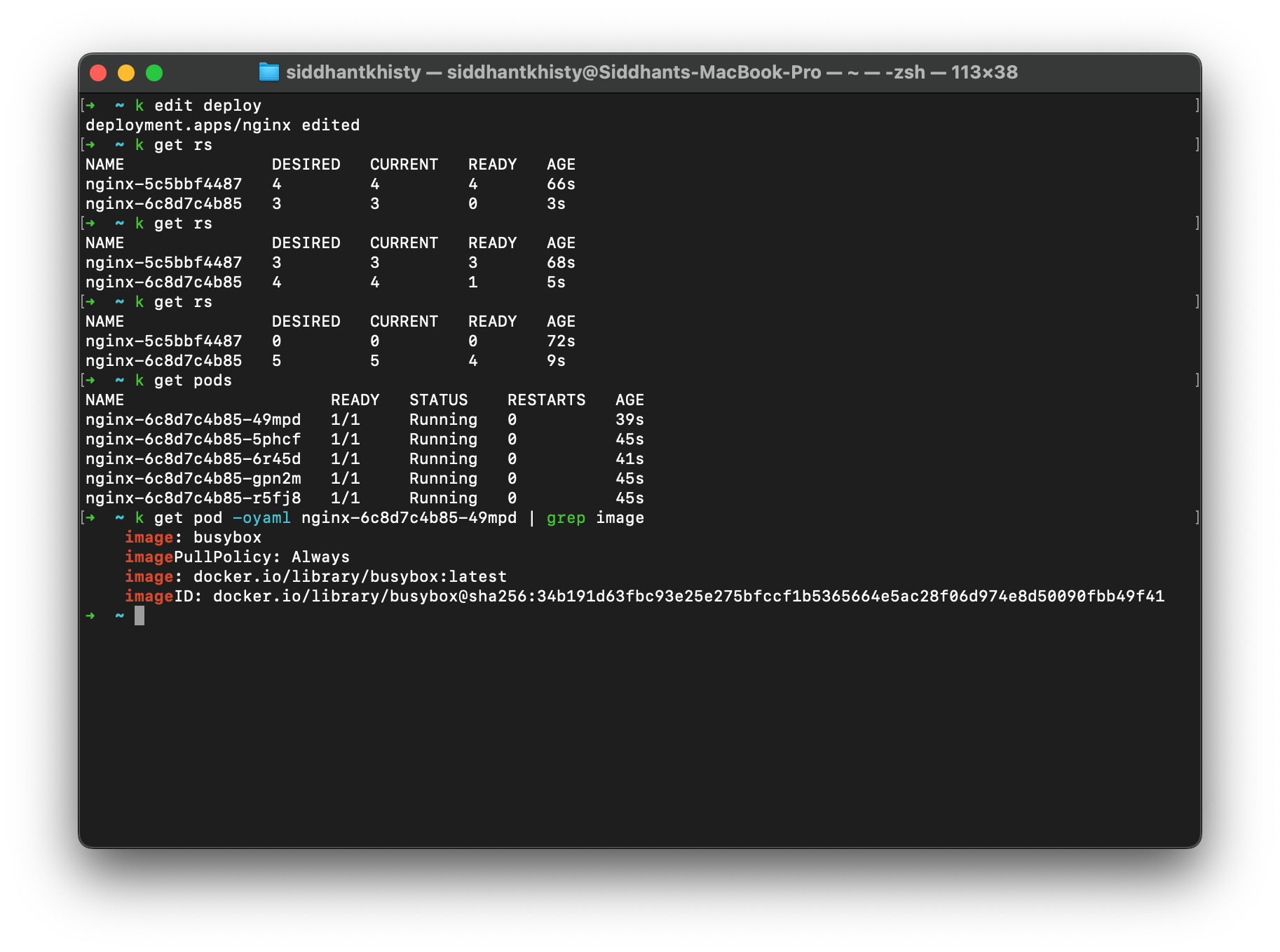
Now, when it comes to updating the deployment, a similar set of steps will be followed. First, the deployment will create a new ReplicaSet which will have the updated configuration. Depending on the defined rollout strategy, the old replicaset will start to scale down, while the new ReplicaSet gradually scales up the number of replicas. Eventually, once the old ReplicaSet has scaled down to zero, it will be deleted, and all the running pods will contain the new configuration. Let’s see this in action.
Update the existing deployment to use the busybox image. You can use the deploy command to edit the deployment
kubectl edit deployment nginx
You can observe that a new ReplicaSet has been created and the old one is gradually being scaled down. You can check the pod manifest and you will notice that it is using the new busybox image.
StatefulSets
Deployments are great to ensure that the application pods are always running, but they fall short when dealing with stateful workloads. While they ensure that the pods are running and have up-to-date configurations, they do not maintain the state of the application running. If the pod gets deleted, the data within it is lost as well.
When working with stateful applications such as databases, it is recommended and preferred to use the StatefulSet object. Similar to a Deployment, StatefulSets creates and manages pods. The key difference between the two is that the pods that are created by StatefulSet have a unique identifier, whereas the pods created by Deployments have a random hash appended to the name. Let us understand why this unique identifier is important.
When any information is written to a database, you want to ensure that only one client can write to the database at any given point in time. If more than one client is writing to the database, there is a chance of data corruption occurring. Let’s say that you created a MongoDB deployment that has a persistent volume attached to it. If these multiple instances of MongoDB that are created by the deployment try to store the data to the volume at the same time, there is a risk of data corruption or data loss.
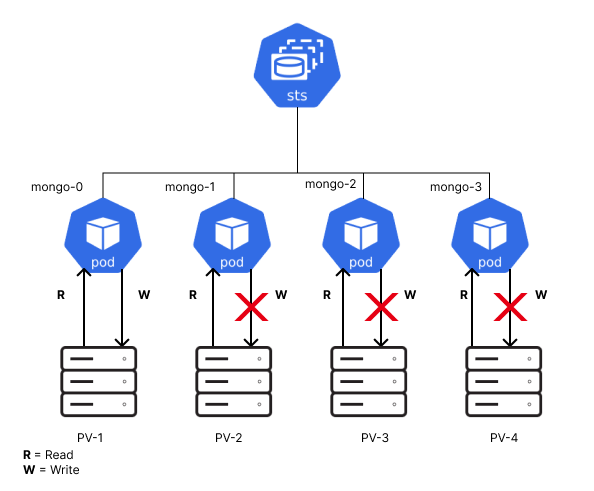
To avoid this type of data corruption, you would use StatefulSets to create and manage stateful applications such as databases. Unlike deployments which have a random hash appended to the pod name, StatefulSets are given unique identifiers such as pod-0, pod-1, and so on.
These unique identifiers create a clear distinction between the different pods which helps maintain data consistency and integrity. There is one primary pod that writes to the actual persistent volume. The other replicas create a clone of the data from the primary pod. Thanks to this, even if one of the pod replicas is deleted, the data will still be available in the other pods. If all the replicas of the StatefulSet are deleted, then the data will be lost, unless it is stored in a persistent storage.
To create a StatefulSet, you first need to create a headless service. As the pods have unique identifiers, StatefulSets also provides each pod with a stable, unique network identity which is crucial for stateful applications like databases that need consistent, stateful connections. Unlike a normal service, a headless service does not provide a load-balancing ClusterIP. Instead, Kubernetes creates unique DNS addresses for each Stateful pod. For example, if the name of the service is mongo-svc for pods created by the mongodb StatefulSet, the DNS entries would be
- mongodb-0.mongo-svc
- mongodb-1.mongo.svc
- mongodb-2.mongo.svc
You can create the headless service by using the following YAML
apiVersion: v1
kind: Service
metadata:
name: mongo-svc
labels:
app: mongodb
spec:
ports:
- port: 27017
name: db
clusterIP: None
selector:
app: mongodbFor now, this service will not target any pods as the StatefulSet has not yet been created. Notice that in the above manifest, the selector is defined as app: mongodb. When creating the StatefulSet, you need to ensure that the pods have the same label.
You can create the StatefulSet with the following YAML
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongodb
spec:
selector:
matchLabels:
app: mongo
serviceName: "mongo-svc"
replicas: 3
template:
metadata:
labels:
app: mongo
spec:
containers:
- name: nginx
image: registry.k8s.io/nginx-slim:0.24
ports:
- containerPort: 27017
name: mongodb
volumeMounts:
- name: www
mountPath: /usr/share/mongo/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "standard"
resources:
requests:
storage: 1Gi
In the above YAML file, a storage class is defined which means that the persistent volumes and PVCs will be dynamically created and bound to the stateful pods. However, if there is no storage class, or if it is of a local storage type, you will need to manually create the PVs and PVCs and ensure that they are bound before creating the Statefulset.
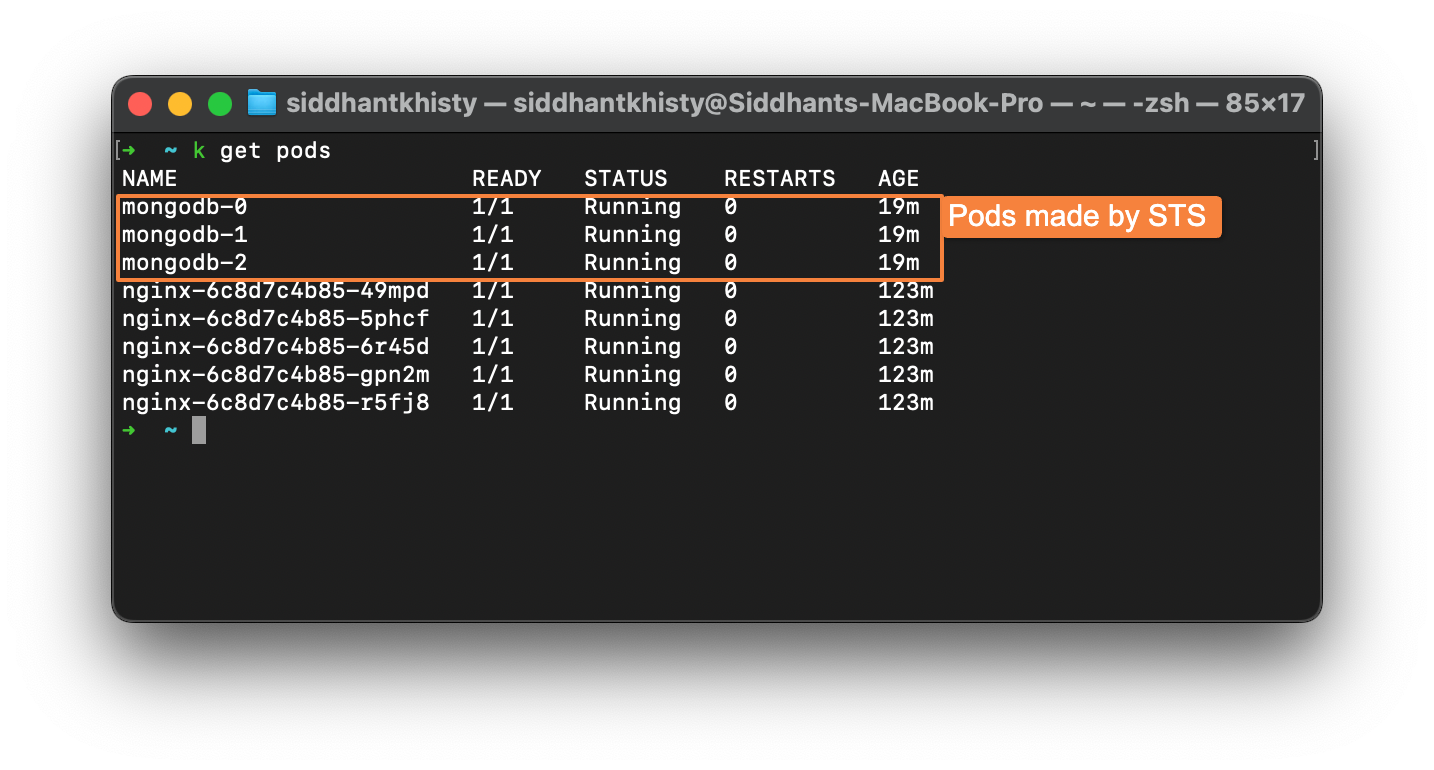
If the StatefulSet is created successfully, you will be able to see the pods with the unique identifiers as such
The difference in attaching volumes for storage in a Deployment and StatefulSet
- Deployments: It is used for “stateless applications”. The volume (PVC) is shared across the pods. Since there is no data in the volume that is shared, it leads to data exposure concerns.
- StatefulSet: It is used for “stateful applications”. The PVC will have information stored in it, and this leads to the sharing of information across all the pods.
Using PVC across Deployments and StatefulSets
PVC can be used across deployments and statefulsets with the help of Access Modes. There are 3 Access Modes, namely
- ReadWriteOnce: Mount the volume as read-write by a single node.
- ReadOnlyMany: Mount the volume as read-only to many nodes.
- ReadWriteMany: Mount the volume as read-write by many nodes.
Deployments
When PVC is specified for deployments, it is shared across all the replica pods. In such a case, PVC must have ReadWriteMany or ReadOnlyMany access mode (ReadWriteMany is rare, it is provided by only a few storage providers).
If you create a PVC with ReadWriteOnce access mode, and then you try to create a deployment that runs a stateful application. It will work fine, till you don’t scale your deployment. If you scale your deployment, you’ll get an error that the volume is already in use, when a new pod starts.
So, it is better to use a read-only volume to avoid errors, in such cases.
StatefulSet
When a PVC is specified for statefulset, you must ensure that the PVC has ReadWriteOnce access mode. With statefulset, you define a VolumeClaimTemplate, so a new PVC is created for each replica automatically.
Another benefit is that you will have one file that defines your application as well as persistent volume. It will further bolster the scalability of your application.
Conclusion
Deployments are useful for deploying stateless applications on Kubernetes clusters, and ensure that the application pods are running at all times. However, when you try to deploy stateful applications such as databases, there can be certain problems that arise. The pods may all try to write to the database at the same time, which can lead to data corruption and data loss.
StatefulSets are designed for handling stateful applications such as databases. They have unique identifiers and it is made sure that only one of the pods can write to the volumes at any given point of time. All the replicas clone the data and hence can maintain the application state. If all the pods are deleted, the data is lost unless it is stored in a persistence storage.






