On March 14th, 2023 - Pi Day - Reddit went dark. A Kubernetes upgrade had triggered a cascading failure across critical services. What should have been a routine version bump turned into a global outage. Engineers scrambled, rollbacks failed, and the root cause turned out to be depressingly ordinary: deprecated APIs that were still in production.
It's easy to read incidents like that and think, "That won't happen to us." But if you're running Kubernetes at any scale, you know how fragile that confidence can be.
The Architectural Fragmentation Problem
Traditional Kubernetes management approaches suffer from fundamental architectural limitations. Organizations typically deploy disparate tools for different operational concerns: separate systems for deployment, monitoring, security scanning, and upgrade planning. This fragmentation creates information silos that obscure critical interdependencies during upgrade cycles.
Consider the typical pre-upgrade assessment workflow:
- Manual reconciliation of workload inventories across namespaces
- Cross-referencing multiple data sources for API usage patterns
- Coordinating between disconnected toolchains to assess readiness
- Synthesizing disparate reports into actionable upgrade plans
Each interface boundary introduces potential for oversight. Critical compatibility issues hide in the gaps between tools, emerging only during production upgrades when remediation options are most constrained.
The problem extends beyond mere inconvenience. When your observability stack operates independently from your deployment pipeline, which itself remains disconnected from your policy enforcement layer, you're essentially navigating upgrade risks with incomplete visibility. It's akin to piloting through fog with instruments that don't communicate with each other.
The Compounding Risk of Tool Proliferation
Every additional tool in your Kubernetes management stack introduces its own upgrade cadence, compatibility matrix, and failure modes. The mathematical reality is sobering: if each tool has a 99% compatibility rate with a new Kubernetes version, ten tools compound to roughly 90% overall compatibility. Add API deprecations, CRD version conflicts, and webhook compatibility issues, and the risk profile becomes exponentially complex.
This complexity manifests in several ways:
- Version drift: Different tools supporting different Kubernetes versions create temporal misalignment
- Feature lag: New Kubernetes capabilities remain inaccessible until all tools update
- Integration brittleness: Inter-tool dependencies create hidden failure chains
- Knowledge fragmentation: Expertise becomes siloed across tool-specific domains
Systemic Requirements for Upgrade Resilience
The Kubernetes upgrade process fails because it exposes fundamental issues in operational architecture. What teams need is a unified platform that enables operation across multiple Kubernetes clusters through a single interface, encompassing visualization, operations, workload management, and cluster upgrade compatibility checks.
A systems-level approach to upgrade risk mitigation requires:
Comprehensive Resource Discovery: Automated enumeration of all workloads, configurations, and dependencies across clusters, with particular attention to custom resources and operator-managed components.
API Deprecation Analysis: Proactive identification of deprecated API usage patterns before they become breaking changes, including transitive dependencies through admission webhooks and custom controllers.
Workload Compatibility Assessment: Deep inspection of container images, init containers, and sidecar patterns to identify version-specific dependencies that might break post-upgrade.
Dependency Graph Visualization: Clear representation of inter-service dependencies, allowing teams to understand upgrade impact radius and plan staged rollouts.
The Unified Platform Paradigm
The risk reduction achieved through unified platforms extends beyond individual capabilities:
Reduced Operational Complexity: Consolidating upgrade assessment within the primary platform interface eliminates context switching costs and reduces likelihood of overlooked resources. When upgrade compatibility checks exist alongside deployment workflows, teams naturally incorporate upgrade readiness into their regular operational cadence.
Enhanced Feedback Loops: Tight integration between assessment and deployment creates rapid feedback cycles. Teams discover and remediate compatibility issues during regular development rather than dedicated upgrade preparation phases. This shift from reactive to proactive upgrade management fundamentally changes the risk profile.
Institutional Knowledge Capture: Unified platforms systematically capture upgrade patterns and remediation strategies, transforming individual expertise into organizational capability. When upgrade experiences feed back into the platform's knowledge base, future upgrades benefit from accumulated wisdom.
How Devtron Enhances Kubernetes Cluster Upgrade Reliability
The operational reality of Kubernetes upgrades demands precision tooling that bridges the gap between cluster state awareness and upgrade execution. Devtron addresses this challenge through systematic pre-upgrade analysis that transforms uncertainty into predictable operations.
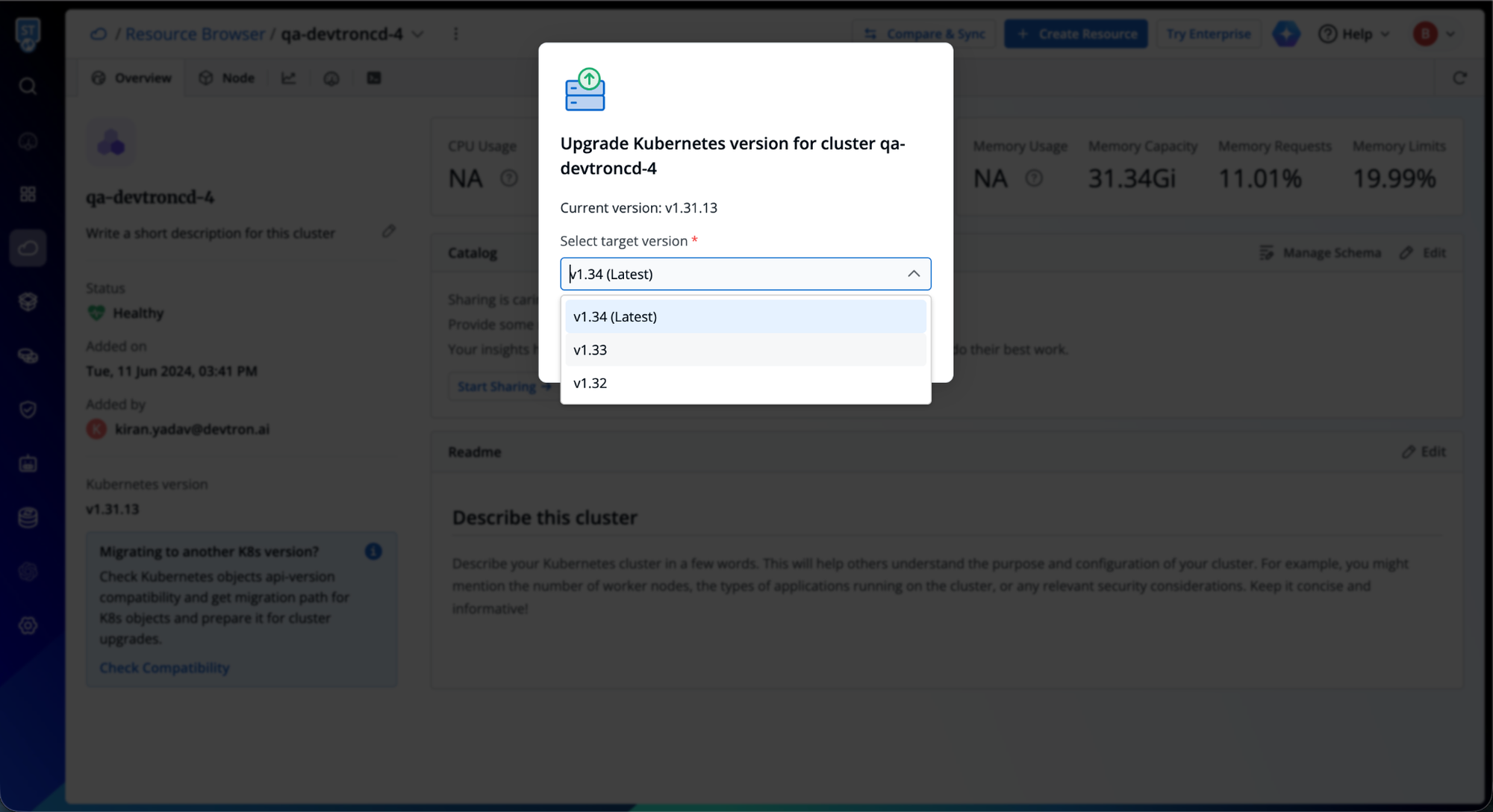
Comprehensive Compatibility Assessment
Devtron's upgrade compatibility engine performs deep inspection across all cluster resources, evaluating each against the target Kubernetes version's API specifications. This analysis extends beyond surface-level checks, examining custom resource definitions, admission webhooks, and operator-managed resources that often harbor hidden incompatibilities. The platform presents findings through a risk-stratified interface, enabling engineers to prioritize remediation efforts based on actual impact potential rather than guesswork.
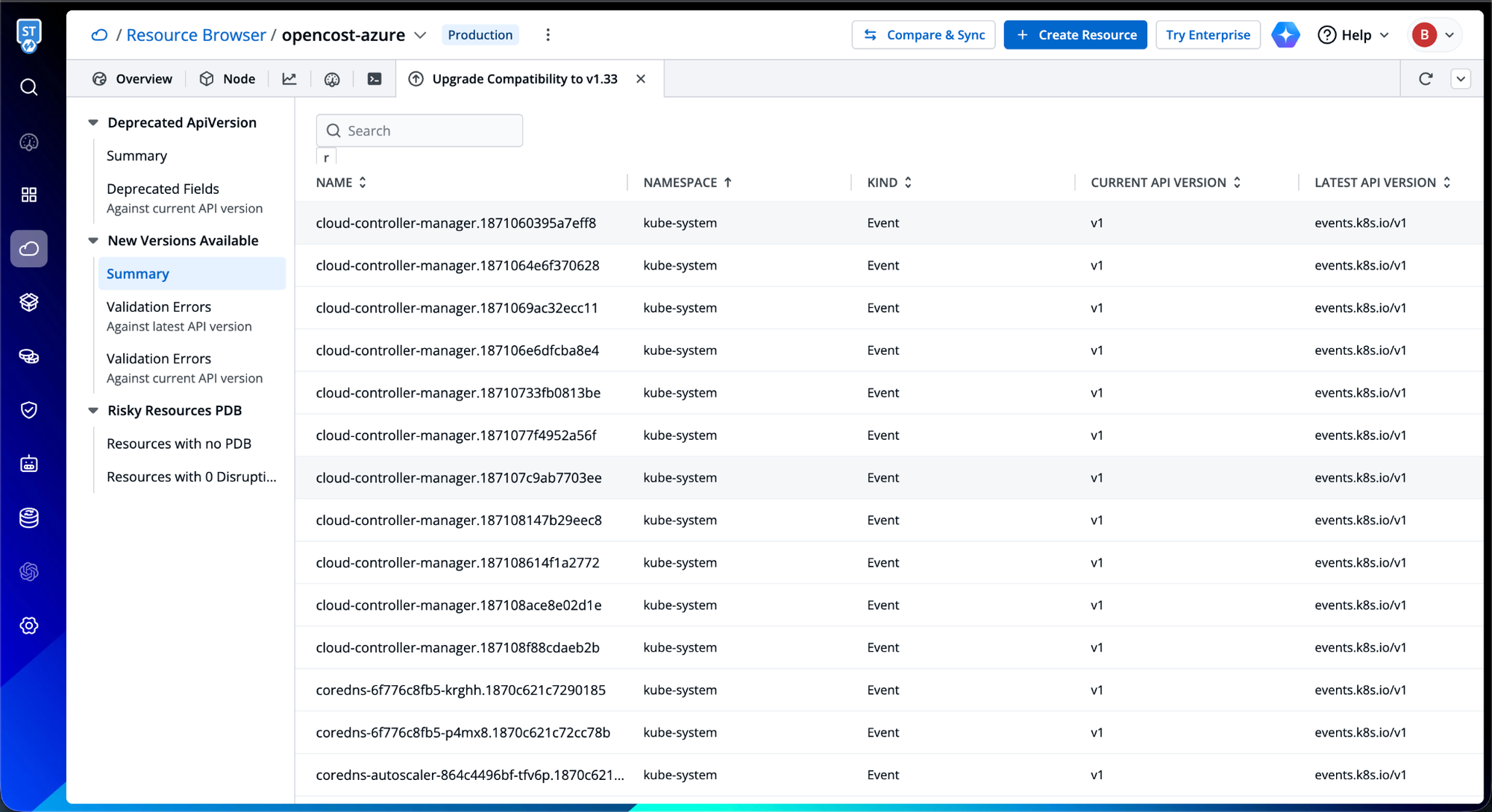
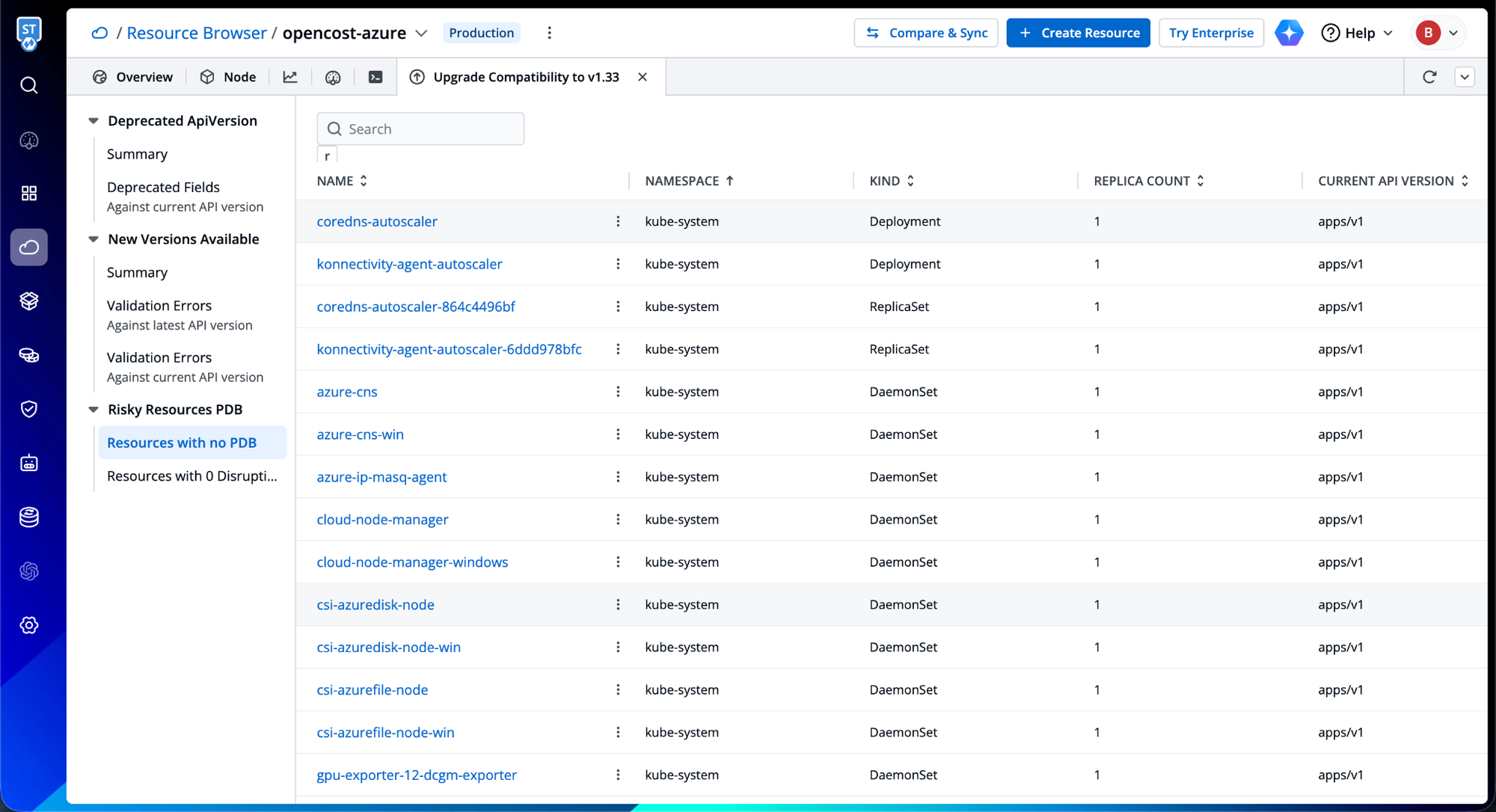
Pod Disruption Budget Analysis
Perhaps most critically, Devtron surfaces resources operating without Pod Disruption Budgets, a common oversight that transforms routine upgrades into availability incidents. The platform identifies stateful workloads, critical services, and singleton pods that lack PDB protection, quantifying the potential blast radius of node drains during upgrade operations. This proactive identification enables teams to implement appropriate disruption budgets before initiating cluster upgrades.
By consolidating these capabilities into a unified workflow, Devtron transforms Kubernetes upgrades from high-stakes operations into predictable, manageable processes. The platform's approach reflects a fundamental truth: reliable upgrades emerge not from hoping nothing breaks, but from knowing exactly what might break and addressing it systematically beforehand.