
Your Kubernetes cluster looks healthy, applications are performing as expected, and traffic patterns haven't changed significantly, yet cloud costs continue to climb. When teams investigate, they often find the same issue recurring across environments: “workloads reserving far more resources than they ever consume.”
This hidden inefficiency is known as over-provisioning. This approach helps teams to prepare for unexpected spikes and maintain reliability. But at scale, excessive CPU and memory allocations lead to underutilised nodes, inflated infrastructure footprints, and cloud spend that grows much faster than actual business demand.
Where the Waste Actually Comes From
Most Kubernetes waste isn't created by a single misconfiguration or architectural mistake. Resource requests based on estimates, environments that outgrow their purpose, workloads that are never right-sized, and infrastructure that remains provisioned long after demand has changed.
1. Resource Requests That Are Never Revisited
Consider a service is deployed with 1 CPU and 2Gi of memory to avoid performance risks. Months later, production metrics show it consistently consumes less than 200m CPU and 500Mi memory, but the original allocation remains unchanged.
The workload runs without issues, yet Kubernetes continues scheduling capacity based on those requests, forcing clusters to reserve resources that are rarely used.
Example:
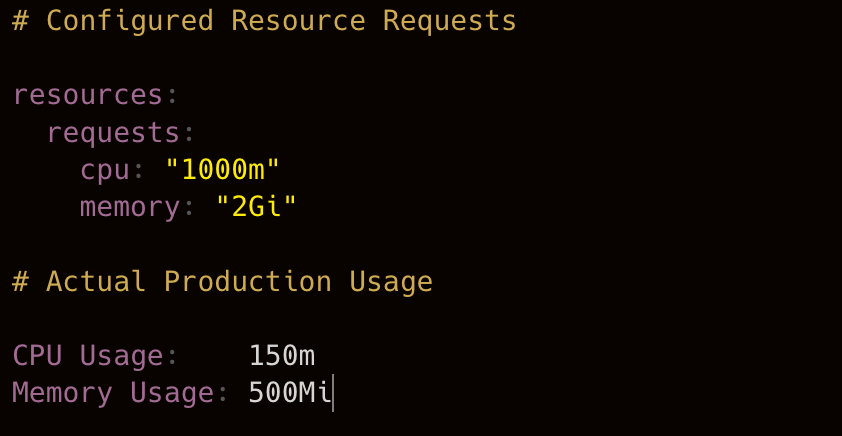
The application continues to perform as expected, so the allocation is rarely questioned.
Over time, these unused resource reservations accumulate across services, increasing infrastructure requirements without delivering any meaningful operational benefit.
2. Production-Sized Non-Production Environments
Production environments are often used as the blueprint for staging and development clusters. During initial setup, this approach simplifies testing and deployment consistency, but infrastructure sizing rarely evolves as usage patterns change.
A staging cluster running 10 nodes and a production-grade database may only serve internal testing traffic, while development environments often remain active around the clock despite being used only during business hours. The infrastructure was designed for production-level demand, but the workload never required it.
While maintaining environment parity is important, matching infrastructure size to production is often unnecessary. As these environments grow over time, they become one of the largest sources of underutilised capacity across Kubernetes deployments.
3. Forgotten Infrastructure
Not all infrastructure waste comes from active applications.
A temporary namespace created for a feature branch, a database provisioned for testing, or a storage volume attached to a short-lived workload may remain active long after development work has ended. Because these resources continue operating without generating alerts or incidents, they often go unnoticed.
Individually, these resources rarely have a meaningful impact on infrastructure costs. Across multiple clusters and environments, however, they gradually accumulate into a persistent layer of waste that delivers little operational value.
4. Autoscaling on Top of Oversized Requests
Autoscaling is often viewed as a safeguard against inefficient resource allocation. In practice, however, autoscalers can only make decisions based on the resource requests and limits provided to them.
If an application requests significantly more CPU and memory than it consumes, Kubernetes still reserves capacity based on those values. As demand increases, the autoscaler responds to the declared requirements rather than actual workload needs, provisioning additional infrastructure to satisfy scheduling constraints.
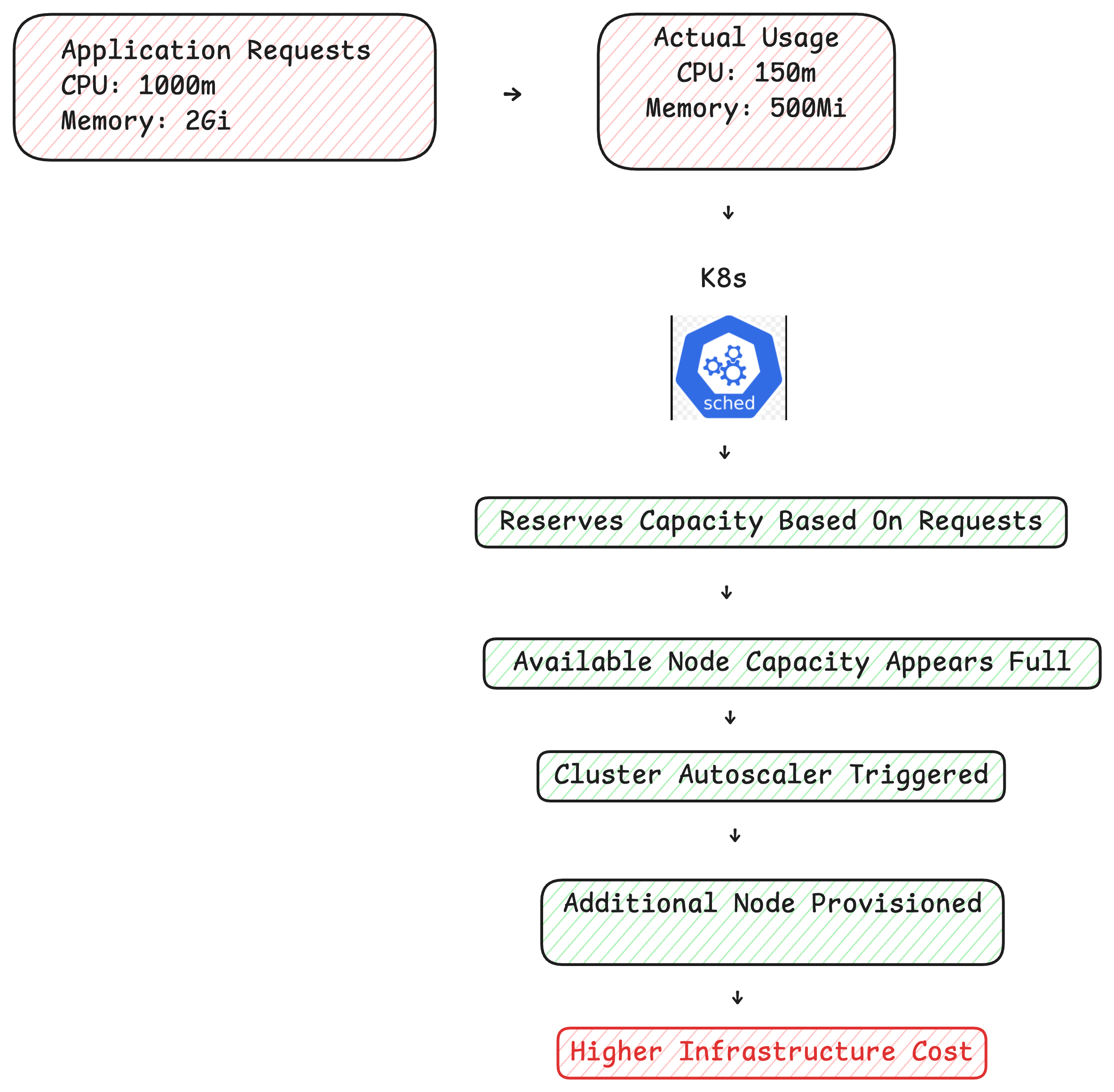
Without proportional increases in workload demand.
Autoscaling remains critical for handling dynamic workloads, but it does not correct inaccurate resource configurations. When oversized requests become the baseline, infrastructure scales around those assumptions, increasing capacity and costs without improving overall utilisation.
Moving From Cost Visibility to Cost Control
Identifying Kubernetes waste is rarely the difficult part. Most platform teams already suspect that resources are being over-allocated, non-production environments are oversized, or dormant infrastructure exists somewhere in the cluster.
The real challenge is understanding where the waste exists, how significant it is, and whether optimisation can be performed safely without impacting application reliability. This is where cost optimisation shifts from monitoring infrastructure to understanding how resources are actually being utilised.
Start with Resource Visibility
Before reducing infrastructure costs, teams need visibility into how resources are actually being consumed across clusters, namespaces, and workloads.
Questions such as:
- Which workloads are consistently underutilised?
- Where do resource requests significantly exceed actual usage?
- Which namespaces consume the most infrastructure resources?
- Which environments contribute most to cluster costs?
Answering these questions requires connecting operational data with cost data.
A healthy cluster doesn't necessarily mean an efficient cluster. Resource utilisation, workload behavior, deployment history, and infrastructure consumption often exist across multiple tools, making it difficult to understand where resources are being underutilised.
This is where platforms like Devtron help by bringing workload insights, deployment visibility, and resource utilisation into a single operational view.
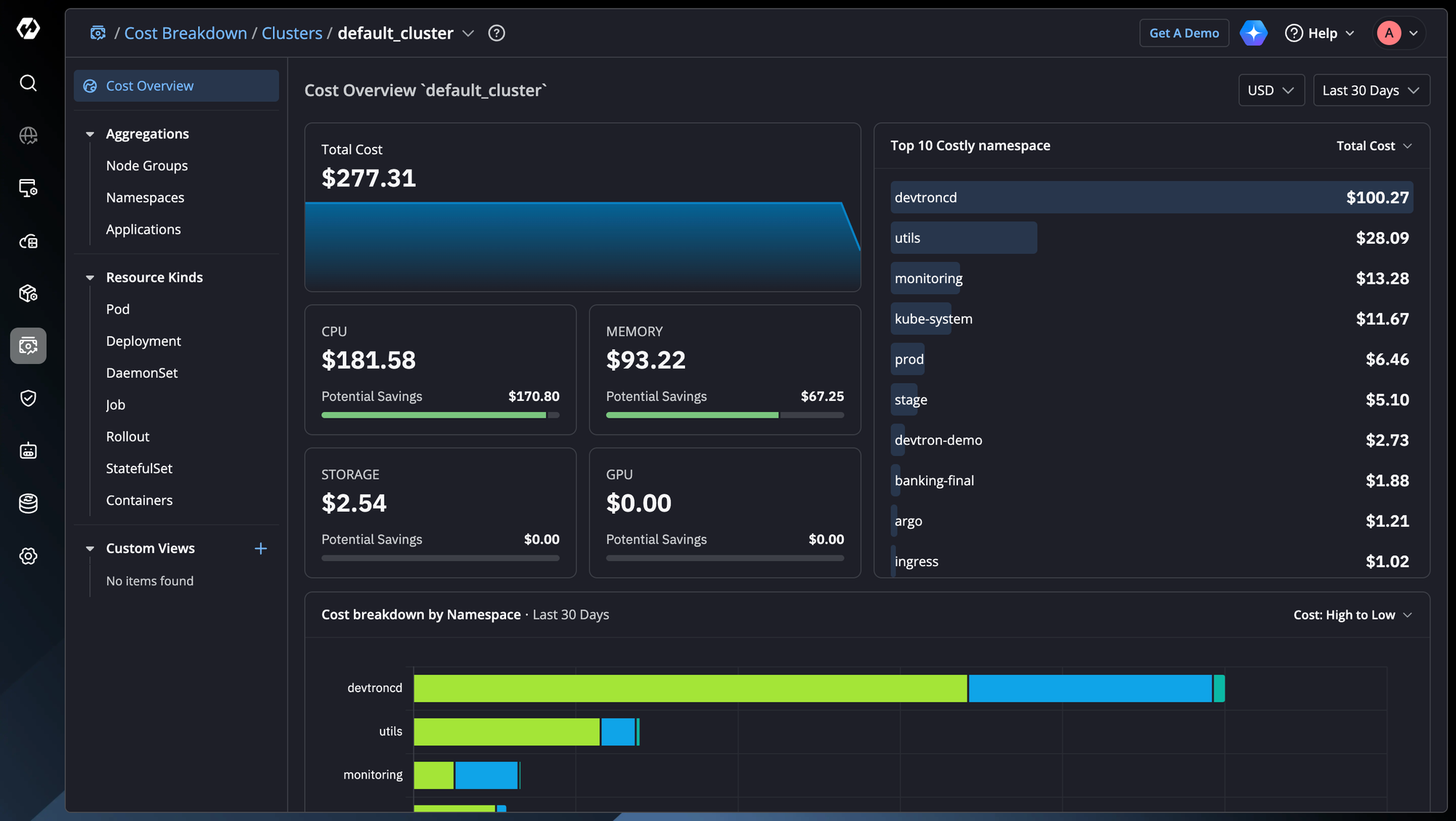
And suddenly the discussion shifts from:
"I think we can reduce these resources.” to: "This workload has consistently used less than 30% of its allocated memory for the past month."
That difference matters because it gives engineering teams confidence to act.
Right-Size Based on Usage, Not Assumptions
One of the safest ways to reduce Kubernetes waste is to replace estimates with production data.
Instead of relying on resource values defined during deployment, teams should continuously evaluate actual utilisation patterns and identify workloads where allocations no longer reflect usage.
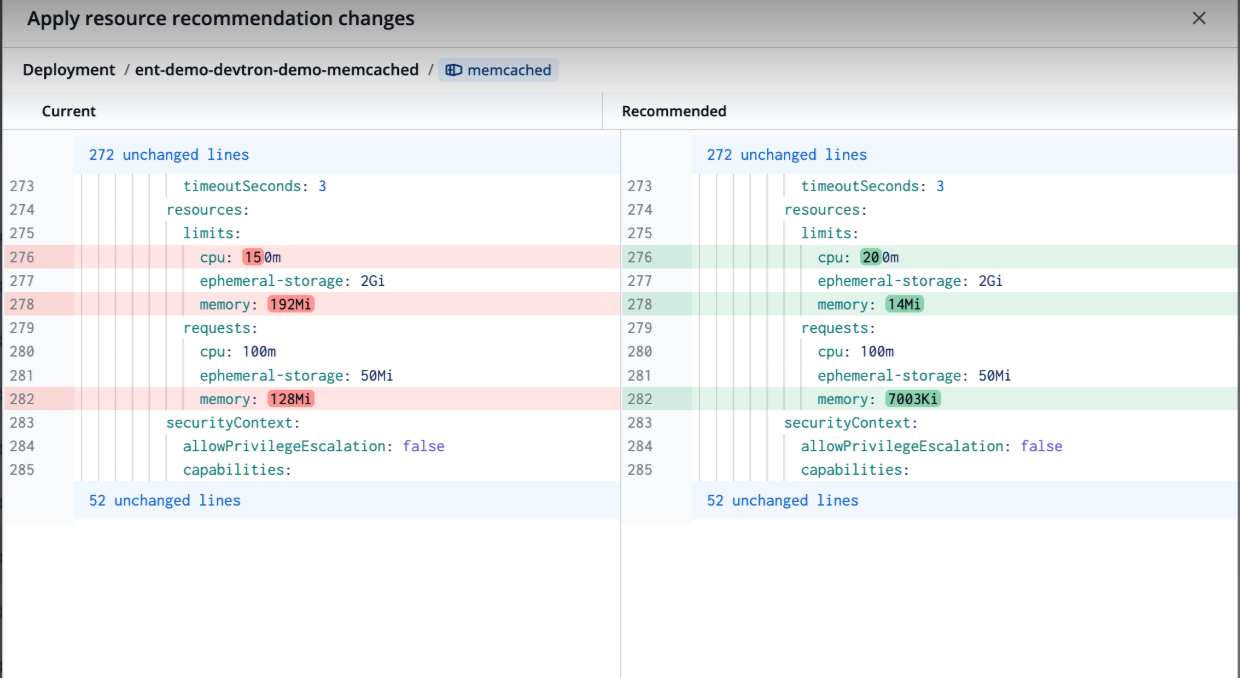
These workloads become immediate candidates for right-sizing.
By continuously reviewing resource allocation against actual consumption, organisations can reduce unnecessary capacity without compromising application performance.
Establish Governance Before Waste Reappears
Resource optimisation is rarely a one-time exercise. New services are deployed, environments evolve, and infrastructure requirements change over time.
Without consistent controls, the same patterns eventually return oversized resource requests, forgotten environments, and infrastructure that no longer reflects actual demand.
To prevent waste from accumulating again, organizations should establish guardrails around resource allocation, ownership, and cost visibility. This can include enforcing resource requests through admission controllers or policy engines, implementing namespace-level cost attribution, and regularly reviewing resource utilisation across environments.
Optimize Resource Allocation Before Infrastructure Pricing
Rightsizing should always come before infrastructure pricing optimization.
Purchasing Savings Plans, or moving workloads to Spot instances, but these strategies are most effective when resource allocations already reflect actual demand. Otherwise, organisations risk committing to capacity that was oversized from the beginning.
The most sustainable cost reductions come from eliminating waste first and optimising infrastructure purchasing decisions second.
Final Thoughts
Kubernetes waste rarely comes from a single decision. It emerges gradually through resource requests that are never revisited, oversized non-production environments, forgotten infrastructure, and scaling decisions based on inaccurate assumptions.
The challenge for engineering teams is no longer collecting more metrics. It is transforming operational data into actionable insights that help teams understand where resources are being consumed and where optimisation opportunities exist.
Organisations that successfully control Kubernetes costs are not necessarily running fewer workloads. They simply have better visibility into how infrastructure is allocated, utilised, and governed across their platform.


